所有的协程共享同一个 CPU,也就共享同样的 16个通用寄存器。如果我们要把 A 协程切换成 B 协程,就要把当前 16个通用寄存器的值存在 A 协程的数据结构里;然后再从 B 协程的数据结构里取出B协程的寄存器的值,写回通用寄存器中。我们还要处理栈。不过栈与寄存器不同,x86-64规定 %rsp寄存器(也是通用寄存器之一)存的值便是栈顶的地址。不同的协程不必共享栈,它们可以分配各自的栈,上下文切换时将%rsp 指向各自的栈顶即可。
因为 x86 的栈是从高地址向低地址增长的,初始栈为空,所以栈顶应该指向co->stack 的最末尾。又因为 x86 的栈必须 16字节对齐,所以执行 (intptr_t)sp & -16LL(-16 低 4 位为0,其它都为 1)得到栈顶地址。然后将栈顶置为co->start,也就是入口函数的地址。最后我们把保存的 rsp寄存器的值设置为栈顶地址,这个值会在 co_ctx_swap被复制到寄存器 %rsp 中。
现在我们的协程已经可以跑起来了。写一个简单的例子试试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
structcoroutine *main_co, *new_co;
voidfoo() { printf("here is the new coroutine\n"); co_ctx_swap(&new_co->ctx, &main_co->ctx); printf("new coroutine resumed\n"); co_ctx_swap(&new_co->ctx, &main_co->ctx); }
这样做的好处是可以节省磁盘:所有软件依赖的相同的库只存在一份。因此安装一个Linux 系统通常只需要几 G 的磁盘空间,而 Windows 通常需要几十G。同时可以节省内存,因为共享库的加载方式是mmap,同一个共享库在内存中也只有一份。
但是这么做是有代价的。假设 A, B 软件都依赖于库 L,那么 A 和 B就只能依赖于同一个版本的库L。一台机器上有这么多软件,意味着整个依赖网络让他们相互钳制,版本号被限制,不能随意升级。一个发行版会确定各种软件包的版本(确定主次版本号,补丁号通常不做限制),组成软件库,确保它们相互兼容,没有依赖冲突。也就是说apt 安装的软件版本由当前 Ubuntu 版本决定的。这也是为什么Linux 发行版通常每年都要发布一个新版本,否则软件库会落后于时代。
]]><p>我们知道,不同于 Windows 将软件的所有文件安装在一个目录,一个 Linux
软件的不同部分会被安装在不同路径。例如,可执行文件安装在
<code>/usr/bin</code> 下;库文件安装在 <code>/usr/lib</code>
下;文档、脚本等资源文件通2023 Annual Reviewhttps://luyuhuang.tech/2024/01/01/2023-annual-review.html2023-12-31T16:00:00.000Z2024-01-01T10:49:09.926ZIn 2023 I spent most of my time on work, learning and dating.Compared with the last year, devoted less time on this blog andcommunity. It might be a pretext but to be honest, writing a blog postalways consumes a lot of my energy, especially when there was a lot ofovertime this year. Anyway, I should write more posts in the new year,and I’ll try to write some non-technical posts (well, partially becausethey’re easy to write (and read)).
Let’s talk a little about professional skills over here. In the past,I focused most of my efforts on coding skill, rather than engineeringskills, or let’s say, the business skills. This is because I love thehacker spirit, and am fascinated by intricate program structures andalgorithms. But your boss just need one who solve problems, them don’tcare about computer science. To solve a problem, you have to considermany things other than the computer - namely, the people around you. Andthat’s exactly what software engineering does - to use some engineeringmethods to prevent or eliminate mistakes made by humans. So when I focuson hacking, I must keep an open mind on other skills, especially thosemethodologies for problem-solving.
Goals
Keep up learning English
Read Understanding the LinuxKernel (I’m not sure if I can finish it)
Keep up daily LeetCodeexercises
Keep up writing blogs, basically one post amonth
Read some non-technicalbooks
Keep up exercises
Learning
I finished learning Structure and Interpretation of ComputerPrograms (SICP), an amazing book. Its content comprised offunctional programming, layering of program and data structure, OOP,infinite streams, the metacircular evaluator, lazy evaluation,compilation principle, etc. I have to say, SICP opened the gateof computer science for me. Before then, I don’t really comprehend theessential of computer science.
sicp
LeetCode
I kept on doing LeetCode like the past few years. The grid looks notbad.
leetcode
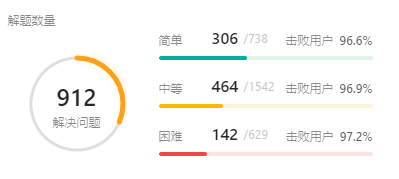
Now I’ve solved 1182 problems. Last year it’s 912, so I solved 270problems in 2023.
Language
I kept learning English in 2023, as I did in the past few years.After continuously learning vocabulary on the APP baicizhan for2024 days, I found it might not be a very effective way to memorize newwords for me at the moment. Therefore, In November, I started learningMerriam-Webster’s Vocabulary Builder. This book organizes wordsby their roots, besides telling you how to use a word, its history, andrelated knowledge.
webster
I also read another amazing vocabulary builder, Word Power MadeEasy. To me, this book like an introduction to the etymology and atthe same time teaches you how to memorize over 3,000 words and continuebuilding your vocabulary.
webster
In addition, I kept leaning Japanese on Duolingo as I did in2022.
webster
Creating
I only wrote 6 posts on the blog.
I created a repo luyuhuang/nvim, but it’sjust for personal configuration, should not be considered as acontribution. I submitted some pull requests and issues to the communityand some of have been accepted.
Something Happy
Hiking and seeing the skyline of the city at the summit is quitehappy, especially with the one you love.
webster
Finally
At the end of a year, I always feel time flies by quickly. But afterI wrote the annual review, I found that the time of a year is quitelong, because you can literally do many things in a year and grow quitea bit in certain aspects (say, I found my English writing skill is muchbetter than the last year). So in the new year, keep learning andgrowing, and I believe we’ll get a better result. Happy New Year toeverybody.
]]><p>In 2023 I spent most of my time on work, learning <span
style="background-color: var(--post-text-color)">and dating</span>.
Compared withScheme 语言https://luyuhuang.tech/2023/07/09/scheme-lang.html2023-07-08T16:00:00.000Z2023-07-09T12:39:58.148Z我最近在读 SICP (Structure and Interpretation of ComputerPrograms),中文译名是《计算机程序的构造与解释》,感觉受益匪浅。我打算开个坑,总结分享一些我学到的内容。SICP综合性非常强,内容包括函数式编程、数据结构的分层与抽象、面向对象、无限流、元循环解释器、惰性求值、非确定性编程、逻辑编程、汇编语言与机器、编译原理等等。我只能选取一个主题抛砖引玉,这个系列文章的主题是continuation,主要内容可能包括:
看到这里,你可能会以为表达式 (if (> a b) a b)也是调用了一个 if函数。但,实际上不是。对函数求值时,会先依次对各个参数求值,然后再调用函数。而对于if 来说,当 (> a b) 为真时,只应该对a 求值,不应该对 b 求值。反之,只应该对b 求值。因此 if不能是函数,应该是一个特殊形。
[1] Structure and Interpretation of Computer Programs,Harold Abelson, The MIT Press
[2] The Little Schemer, Daniel P. Friedman, The MITPress
]]><p>我最近在读 <em>SICP (Structure and Interpretation of Computer
Programs)</em>,中文译名是《计算机程序的构造与解释》,感觉受益匪浅。我打算开个坑,总结分享一些我学到的内容。<em>SICP</em>
综合性非常一种简单的事务实现https://luyuhuang.tech/2023/06/18/simple-transaction.html2023-06-17T16:00:00.000Z2023-06-18T14:22:25.225Z在服务器编程中,事务往往是非常重要的,它的一个很重要的作用就是保证一系列操作的完整性。例如服务器处理某个请求要先后执行a, b 两个修改操作,它们都有可能失败;如果 a 成功了但 b失败了,事务会负责回滚 a 的修改。试想如果 a 操作是扣除余额,b操作是发货,如果发货失败,钱就得退回去。如果服务器使用了支持事务的数据库系统,如MySQL,事情就很好办。否则的话,实现类似的逻辑会比较棘手,也很容易犯错。
local original_pcall = pcall functionpcall(f, ...) begin() local ok, res = original_pcall(f, ...) if ok then commit() else rollback() end return ok, res end
localfunctioncommit() local top = table.remove(stack) localpi = stack[#stack] ifpithen for _, assign inipairs(top) do table.insert(pi, assign) end end end
localfunctionrollback() local top = table.remove(stack) for i = #top, 1, -1do local tab, key, val = table.unpack(top[i], 1, 3) tab[key] = val end end
使用的时候不能直接赋值,需要调用set。当然也可以做成元表,不过我不是很喜欢这样。
1 2 3 4 5 6 7 8 9 10
val = {} functiontest() local old = val set(_G, 'val', 42) set(old, 1, 1) error() end
]]><p>在服务器编程中,事务往往是非常重要的,它的一个很重要的作用就是保证一系列操作的完整性。例如服务器处理某个请求要先后执行
a, b 两个修改操作,它们都有可能失败;如果 a 成功了但 b
失败了,事务会负责回滚 a 的修改。试想如果 a 操作是扣除余额,b
操作是发货,如果发Neovim 使用体验https://luyuhuang.tech/2023/03/21/nvim.html2023-03-20T16:00:00.000Z2023-03-20T17:42:33.692Z我很喜欢 Vim 这种纯键盘的交互方式, 但是我却一直不怎么会用 Vim.虽然熟悉 Vim 的键位, 但是不懂 Vimscript, 不知道怎么装插件, 怎么定制它.因此我一直使用 VSCode 作为主力开发工具, 搭配 VSCodeVim这个插件, 能同时享受到 Vim 和 VSCode 的特性. 但是我总觉得需要会用真正的Vim.
functionlive_grep_opts(opts) local flags = tostring(vim.v.count) local additional_args = {} local prompt_title = 'Live Grep' if flags:find('1') then prompt_title = prompt_title .. ' [.*]' else table.insert(additional_args, '--fixed-strings') end if flags:find('2') then prompt_title = prompt_title .. ' [w]' table.insert(additional_args, '--word-regexp') end if flags:find('3') then prompt_title = prompt_title .. ' [Aa]' table.insert(additional_args, '--case-sensitive') end
opts = opts or {} opts.additional_args = function()return additional_args end opts.prompt_title = prompt_title return opts end
localfunctionhome() local head = (vim.api.nvim_get_current_line():find('[^%s]') or1) - 1 local cursor = vim.api.nvim_win_get_cursor(0) cursor[2] = cursor[2] == head and0or head vim.api.nvim_win_set_cursor(0, cursor) end
vim.api.nvim_create_autocmd('BufReadPost', {callback = function() local line = vim.fn.line('\'"') if line > 1and line <= vim.fn.line('$') then vim.cmd.normal('g\'"') end end})
vector<vector<int>> buildGraph(vector<vector<int>> &matrix) { int M = matrix.size(), N = matrix.front().size(), P = M * N; vector<vector<int>> G(P); vector<int> aux;
aux.resize(N); for (int i = 0; i < M; ++i) { // 考虑每行 for (int j = 0; j < N; ++j) aux[j] = j; sort(aux.begin(), aux.end(), [&](int a, int b){ return matrix[i][a] < matrix[i][b]; });
for (int k = 1; k < N; ++k) { int p = i * N + aux[k-1], q = i * N + aux[k]; G[p].push_back(q); // 较大元素加入较小元素的邻接列表 } }
aux.resize(M); for (int j = 0; j < N; ++j) { // 考虑每列 for (int i = 0; i < M; ++i) aux[i] = i; sort(aux.begin(), aux.end(), [&](int a, int b){ return matrix[a][j] < matrix[b][j]; });
for (int k = 1; k < M; ++k) { int p = aux[k-1] * N + j, q = aux[k] * N + j; G[p].push_back(q); // 较大元素加入较小元素的邻接列表 } }
vector<int> bfs(vector<vector<int>> &G, vector<int> &in){ // in 数组记录每个节点的入度 int P = G.size(); // P = M * N, 节点总数量 deque<int> Q; vector<int> ans(P, 1); for (int i = 0; i < P; ++i) // 从所有入度为 0 的节点开始 if (in[i] == 0) Q.push_back(i);
while (!Q.empty()) { int p = Q.front(); Q.pop_front(); for (int q : G[p]) { ans[q] = max(ans[q], ans[p] + 1); if (--in[q] == 0) // 如果所有节点的入度都计算过, 则秩已经确定, 可以入队了 Q.push_back(q); } } return ans; }
上面是一个使用广搜的拓扑排序算法.前面建图的时候需要顺便求出每个节点的入度, 存放在 in 数组中.因为图中不会有环, 所以当队列 Q 为空时,所有节点的秩都已计算完毕.
intfind(vector<int> &pi, int a){ if (pi[a] == a) return a; return pi[a] = find(pi, pi[a]); } voidmerge(vector<int> &pi, int a, int b){ a = find(pi, a), b = find(pi, b); if (a != b) pi[a] = b; }
vector<vector<int>> matrixRankTransform(vector<vector<int>>& matrix) { int M = matrix.size(), N = matrix.front().size(), P = M * N;
// 1. 并查集合并相同元素 vector<int> pi(P); // 并查集用到的 pi 数组 vector<vector<int>> rows(M, vector<int>(N)), cols(N, vector<int>(M)); // 记录排序后的各行各列 for (int i = 0; i < P; ++i) pi[i] = i; for (int i = 0; i < M; ++i) { auto &aux = rows[i]; for (int j = 0; j < N; ++j) aux[j] = j; sort(aux.begin(), aux.end(), [&](int a, int b){ // 对每行排序 return matrix[i][a] < matrix[i][b]; }); for (int k = 0; k < N;) { int j = aux[k], n = matrix[i][j]; while (k < N && n == matrix[i][aux[k]]) // 用并查集合并相同的元素 merge(pi, i*N + j, i*N + aux[k]), ++k; } } for (int j = 0; j < N; ++j) { auto &aux = cols[j]; for (int i = 0; i < M; ++i) aux[i] = i; sort(aux.begin(), aux.end(), [&](int a, int b){ // 对每列排序 return matrix[a][j] < matrix[b][j]; }); for (int k = 0; k < M;) { int i = aux[k], n = matrix[i][j]; while (k < M && n == matrix[aux[k]][j]) // 用并查集合并相同的元素 merge(pi, i*N + j, aux[k]*N + j), ++k; } }
// 2. 建图 vector<vector<int>> G(P); vector<int> in(P); // in 数组记录入度 for (int i = 0; i < M; ++i) { // 考虑每行 auto &aux = rows[i]; for (int k = 1; k < N; ++k) { int p = find(pi, i*N + aux[k-1]), q = find(pi, i*N + aux[k]); // 要找到并查集的根节点 if (p != q) G[p].push_back(q), // 较大元素加入较小元素的邻接列表 ++in[q]; // 较大元素的入度加一 } } for (int j = 0; j < N; ++j) { // 考虑每列 auto &aux = cols[j]; for (int k = 1; k < M; ++k) { int p = find(pi, aux[k-1]*N + j), q = find(pi, aux[k]*N + j); // 要找到并查集的根节点 if (p != q) G[p].push_back(q), // 较大元素加入较小元素的邻接列表 ++in[q]; // 较大元素的入度加一 } }
// 3. 广搜 deque<int> Q; vector<int> abstract(P, 1); for (int i = 0; i < P; ++i) if (find(pi, i) == i && in[i] == 0) Q.push_back(i); // 只有并查集的根节点才能参与广搜 while (!Q.empty()) { int p = Q.front(); Q.pop_front(); for (int q : G[p]) { abstract[q] = max(abstract[q], abstract[p] + 1); if (--in[q] == 0) Q.push_back(q); } } vector<vector<int>> ans(M, vector<int>(N)); // 构造结果 for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) ans[i][j] = abstract[find(pi, i*N + j)]; // 根节点的结果就是这个元素的结果
2022 is a bit tough for many of us. The pandemic disturbed manypeople’s life. The Chinese internet industry is not that prosperous inthe year: many companies layoffs and many people are unemployed, manygame projects were aborted due to suspended issued publishing licenses,many companies’ share prices fell, and so on. I was infected withCOVID-19 at the end of 2022 and suffered from fever, body aches, andfatigue for a week.
Anyway, It’s worth celebrating at the beginning of 2023 as I’m stillalive, I still have a job, and I’ve done some meaningful work in theyear. We still hope that the world will be better and that all wishescome true.
Goals
I finished some of the new year’s resolutions for 2022.
Keep up learning English.
Finish reading C++Primer
Read Understand the LinuxKernel(4 chapters)
Keep up daily LeetCodeexercises
Keep up writing blogs, at least one post amonth (only 9 posts)
Keep up exercises (running, push-up)(did not run, just push-ups every day)
Learning
On weekends, I usually spend time reading tech books.
Finished reading C++ Primer. Last year I read half ofit.
Read 4 chapters of Understand the Linux Kernel.
LeetCode
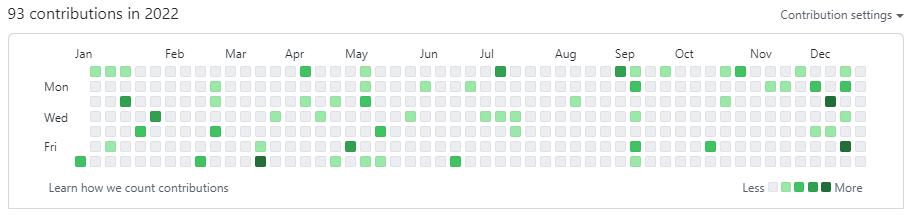
This year I spent lots of time doing LeetCode, basically everyday.
leetcode
Now I’ve done 912 exercises, I think it might be a small achievementthat’s not very easy to achieve. Doing LeetCode has somewhat improved mycoding skill and logical mind. it’s a good habit that’s worth keepingup.
leetcode
Language
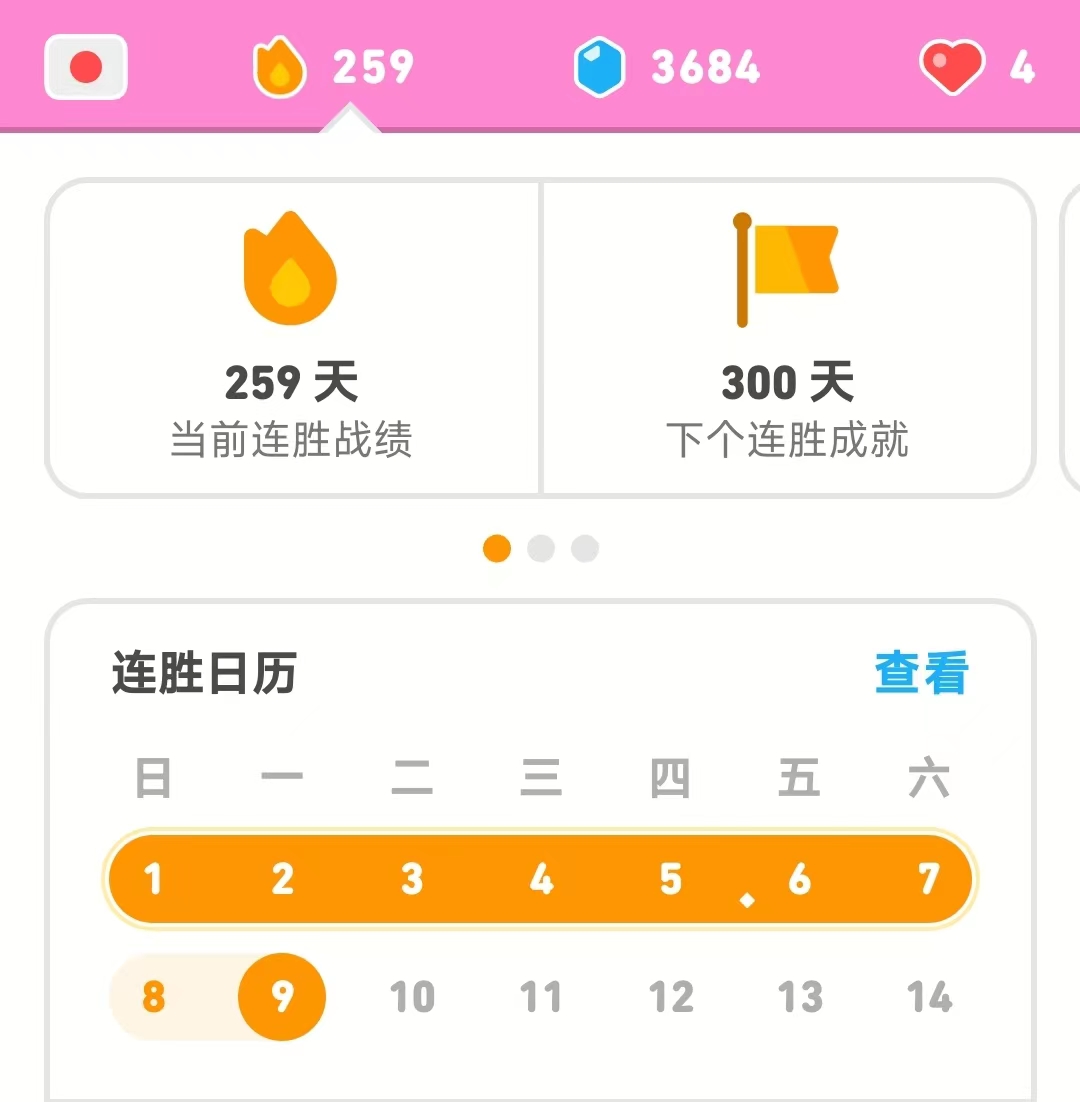
English learning is not easy. I’ve spent plenty of time learningEnglish, including memorizing words and practicing listening andspeaking. I insist on memorizing words every day this year and untilnow, I’ve used Baicizhan to insist on memorizing words for 1709days.
English
I also spent lots of time on Open Language to practice listening andspeaking. It helped a lot at the beginning, but now I feel it doesn’thelp much. I think I’ve hit the English learning plateau.
In addition to English learning, I’ve been learning Japanese onDuolingo. I didn’t spend much time on that, basically two units a day.It’s just for fun.
duolingo
Creating
(only) Wrote 9 post on my blog.
This year I didn’t create much work in my spare time. I intended touse C++ to write a VPN software, but I only completed the most basicfeature and have not released an initial version. I just had somesporadic commit records on Github.
github
Something Happy
The happiest thing is that I’ve had a good time with the people Ilove. Thanks for her company to make me no longer feel lonely.
flowers
Finally
Not long ago I revisited My Life as McDull (麦兜故事), afamous Hongkong film I watched when I was a kid. But I didn’t understandits profound central idea at that age. I love what it said at theending:
Roasted chicken is easy to cook. The material is a chicken; themethod is to take a chicken and roast it, and then it’s done. If youwant it to be delicious, the secret is to cook it better.
mcdull
Well, life might be a simple process from birth to death. It’ssimple, but it also can be complicated if you want. If you want it to bebeautiful, the secret is to be positive and try to make it better.
Although we might be going to face challenges in 2023, we stillbelieve that good things are about to happen. Happy New Year to us.
在组合表达式中, 有时可以省略修饰词. 如果一个基本表达式只提供 ID而没有修饰词, 则认为它的修饰词与前一个基本表达式相同. 例如表达式port 22 or 80 or 443, 其中 80 和443 没有修饰词, 则认为它们的修饰词为 port.因此这个表达式等价于 port 22 or port 80 or port 443.