搞清楚令人头疼的乱码问题
相信我们每个人都被乱码的问题困扰过. 乱码常常令人十分头疼, 这主要是因为没有搞清楚字符编码的问题: 何为 encode 何为 decode, UTF-8 和 Unicode 是什么关系, 它与 UTF-16 和 UTF-32 的区别又是什么, BOM 头又是什么东西等等. 这里我们彻底地捋一遍字符编码问题. 首先搞清楚几个概念:
基本概念
字符
字符指语言中的书写原子, 是不可再分的最小单元, 例如字母
aé, 表达符号;。, 汉字阿, 假名あ, emoji😂等等. 总之是书写的最小单位, 它们都应该看作一个字符.字符库
人类的字符太多了, 我们一次用不了这么多. 所以我们根据不同的情况, 取全体字符的一个子集, 形成一个字符库.
编码后的字符
人类写字, 在纸上 “画出” 相应的字形即可. 但计算机不可能处理和存储字形图案, 所以人们给每个字符编一个序号(编码), 计算机就只需操作这些序号即可. 例如字母
a在 ASCII 中的编号为97, 汉字阿在 Unicode 中的编号为38463, 在 GBK 中的编号为45218.编码后的字符集(coded character set)
为字符库中的每个字符分配一个唯一的编码, 并把编码唯一映射到字符. 也就是说编码后的字符集是一个编码到字符的映射. Unicode, GBK, iso-8859-1 等都是编码后的字符集
字符编码方案(character encoding scheme)
把一个字符串的每个字符都编上号了, 怎么存储这些编号呢? 目前 Unicode 编码的最大值达 0x10FFFF, 需要 21 位二进制数; 然而每个字符的编码大小不一, 如果简单地将一个字符分配三字节的话, 未免太浪费空间了. 这个时候我们就需要字符编码方案, 将这些字符编码转换成二进制字节流. UTF-8 就是一种字符编码方案, 它采用变长编码, 能够有效节省空间.
实际上, 我们平时常说的 “这个文件使用 UTF-8 编码”, 准确地说应该是 “这个文件使用 Unicode 字符集和 UTF-8 编码方案”.
工作流程
我们来看看计算机是如何使用编码后的字符集和字符编码方案写入和读取文本文件的.
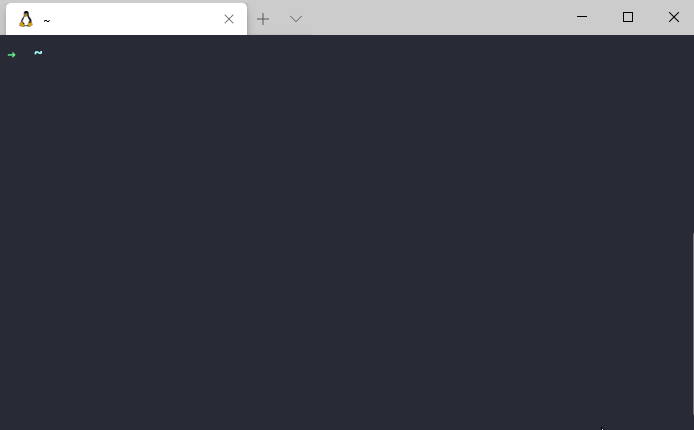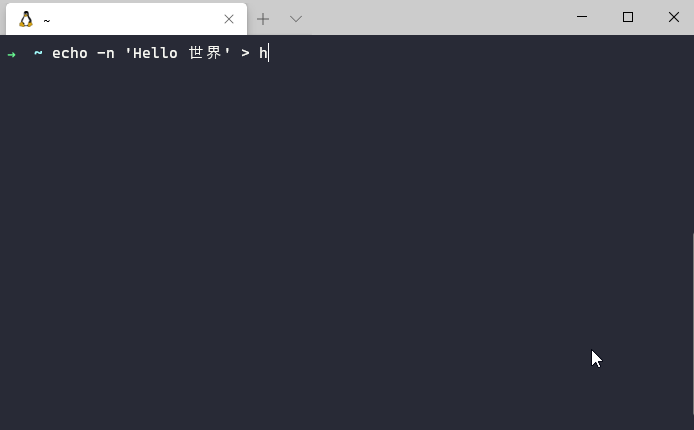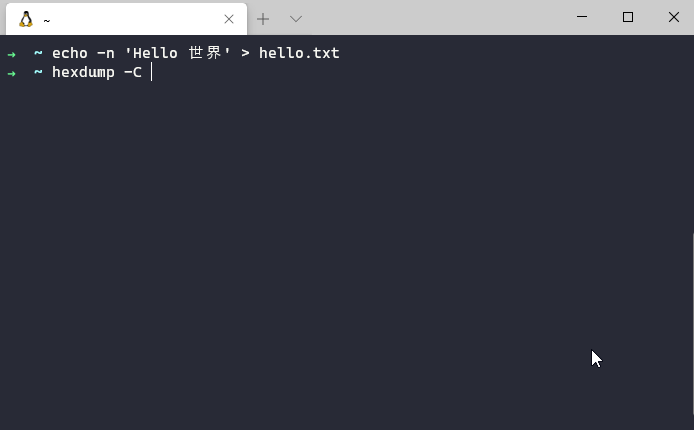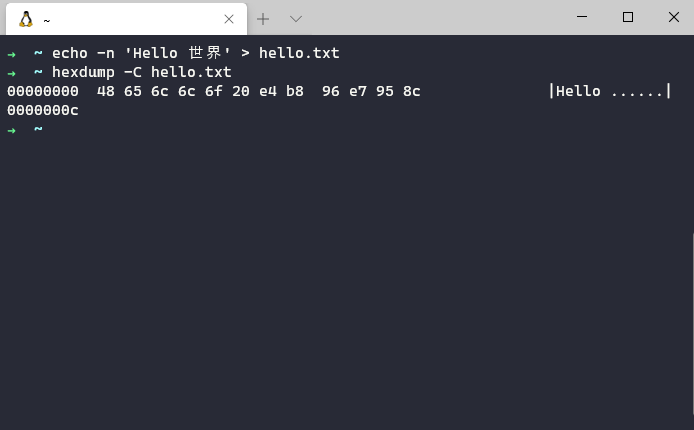
例如, 对于字符串 Hello 世界, 使用 Unicode 字符集编码, 可得到编码序列 [72, 101, 108, 108, 111, 32, 19990, 30028]; 然后使用 UTF-8 字符编码方案, 可得到二进制字节码 48 65 6c 6c 6f 20 e4 b8 96 e7 95 8c, 长度为 12 字节. 把这 12 字节写入文件, 我们就得到了一个使用 UTF-8 编码的文件了.
新建一个文件 hello.txt, 输入 Hello 世界 然后以无 BOM 头 UTF-8 保存, 然后用二进制文件查看器打开, 就能看到它的二进制字节码了.
读取文本文件其打印或显示出来的过程与之相反. 先使用字符编码方案将二进制字节码解码为字符代码, 然后使用编码后的字符集将字符代码映射成字符; 要想打印或显示这些字符, 就需要加载字体, 将字符转换成相应的成字形. 整个流程如下所示:

不同语言中的字符串和编码
对于不支持 Unicode 的语言, 如 C 或 Lua, 它们的字符串都可以看作单字节 (8 位) 整数序列. 它们读入文件时, 会把文件的每一个字节原样复制在内存中, 因此实际上它们是不区分文本文件和二进制文件的. (C 语言调用 fopen 可以在 mode 参数中包含 b 表示以二进制打开, 这是为了兼容某些奇怪的系统 (没错, 说的就是 Windows), 不是为了编码.) 可以说, 这样的语言其实是 “不认识” 字符的. 例如, 用 C 语言读入上述的 hello.txt 文件, 得到的字符串长度就是 12, 而这个字符串实际的字符数应该是 8.
而对于视字符串为字符序列的语言, 如 Python 或 NodeJS, 情况就不一样了. 例如, Python 在读取文本文件的时候必须要知道它们的编码 (字符编码方案和编码后的字符集), 然后将文件的内容 – – 二进制字节流转换成该 Python 使用的字符集 (也就是 Unicode) 所编码的字符序列(字符串).
在 Python 中使用 open 函数打开一个文件, 它的原型是这样的:
1 | |
其中 encoding 参数指令打开文件的编码, 若不指定, 则使用当前平台的默认编码. 如果我们调用 open("hello.txt", encoding="UTF-8").read(), 就可得到长度为 8 的字符串, 这表明 Python 准确地识别了每一个字符.
我们还可以在 mode 参数中标识该文件是二进制文件, 这样 Python 就不会对文件解码, 而是向 C 语言一样将文件内容原样读取到内存里. 不过 Python 不认为二进制字节流是字符串 (str), 而是字节序列 (bytes). 调用 open("hello.txt", "rb").read() 会得到一个字节序列, 它的长度是 12. 我们可以也调用 bytes.decode 方法将字节序列解码成字符串.
UTF 和 BOM 头
UTF-8, UTF-16 和 UTF-32 都是 Unicode 字符集的不同编码方案. 它们之间的区别就是编码单元的长度: UTF-8 的编码单元为 8 位, UTF-16 为 16 位, UTF-32 为 32 位. 因为目前 Unicode 的单个字符最多需要三个字节存储, 因此 UTF-8 和 UTF-16 都是变长编码. 如何实现变长编码呢? 以 UTF-8 为例, 它的一个字符会占用一至四字节. 它会在第一字节中标记这个字符占用的字节数: 0 开头表示占用 1 字节, 110 开头表示占用 2 字节, 1110 开头表示占用 3 字节等; 第二至四字节始终以 10 开头. 如下表所示:
| 1st byte | 2nd byte | 3rd byte | 4th byte |
|---|---|---|---|
0xxxxxxx | |||
110xxxxx | 10xxxxxx | ||
1110xxxx | 10xxxxxx | 10xxxxxx | |
11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
这样 1 字节的 UTF-8 可表示 7 位, 与 ASCII 码兼容; 2 字节的 UTF-8 可表示 11 位, 3 字节可表示 16 位, 4 字节可表示 21 位. 这样, UTF-8 可以为全体 Unicode 码编码. 例如前面提到的汉字 阿 的 Unicode 码为 38463, 二进制就是 0b1001011000111111 共 16 位, 需要使用 3 字节的 UTF-8 码, 编码得到: 11101001 10011000 10111111. 打开 Python 试试:
1 | |
对于 UTF-16 和 UTF-32 这样的编码方案, 因为使用了多个字节表示一个字符, 这就涉及到字节序的问题了. 因此 UTF-16 和 UTF-32 都有大端序和小端序两种. 如何知道一个文件使用的 UTF 码是大端序还是小端序呢? 这就要用到 BOM 头了. 在文件头部加入若干字节的特殊字符, 称之为 “BOM 头”, 来标识这个文件的编码和字节序. 如下表所示:
UTF-8 | - |
ef bb bf |UTF-16 | big endian |
fe ff |UTF-16 | little endian |
ff fe |UTF-32 | big endian |
00 00 fe ff |UTF-32 | little endian |
ff fe 00 00 |UTF-8 的编码单元只有 1 位, 不存在字节序的问题, 因此在 UTF-8 的 BOM 头就有些多余了. 我们常常不会在 UTF-8 文件的开头加上三字节 BOM 头, 这样的文件就是无 BOM 头的 UTF-8 文件.
参考资料:
- HTTP 权威指南, 人民邮电出版社