ZooKeeper 入门教程
ZooKeeper 是一个分布式服务中间件, 乍一看有点像一个 NoSQL 数据库系统. 不过它的主要功能不是存储数据, 而是提供一种共享数据和服务间通信的方式, 使用它我们能够更方便地开发分布式软件. 这篇文章介绍 ZooKeeper 的主要特性, 使用方式和应用场景.
主要特性
我们先来看一下 ZooKeeper 的主要特性, 以及它跟 NoSQL 数据库系统不同的地方.
数据存储
不同于 Redis 的 key-value 结构, ZooKeeper 将所有的数据管理在一个树状结构中. 这个结构很像文件系统, 一个路径标识一个节点, 由若干个用斜杠隔开的名字组成. 根结点路径为 /, 因此路径总是由斜杠开头.
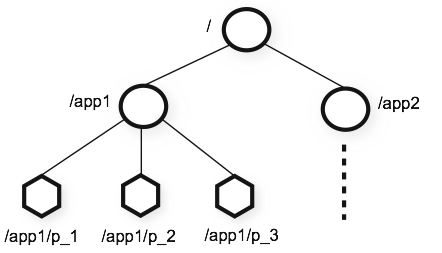
与文件系统不同的是, ZooKeeper 中叶子结点和内部节点都可以存储数据, 这就好比允许一个文件同时也是一个目录. 我们通常称 ZooKeeper 中的节点为 znode. 每个 znode 数据的存取是原子的, 要么一次性取出全部数据, 要么覆盖掉全部数据. znode 的操作十分简单:
- create : 创建一个节点
- delete : 删除一个节点
- exists : 判断节点是否存在
- get data : 获取指定节点的数据
- set data : 设置指定节点的数据
- get children : 获取指定节点的子节点列表
- sync : 等待数据同步 (稍后可以看到, 在集群化部署时需要考虑同步的问题)
观察一个节点
除了可以主动获取一个节点的数据, 我们还可以观察一个节点. exists, get data 和 get children 都可以设置观察. 如果设置了观察一个节点, 那么当这个节点发生改变当时候, 观察者就会收到通知. 例如观察 get data, 就会在节点的数据发生改变时收到通知.
对节点的观察通常是一次性的. 也就是说, 当一个观察会在它触发后立刻被移除. 如果需要继续观察这个节点, 就必须再次设置观察.
节点的权限
ZooKeeper 的每个节点都可以单独设置权限, 称为访问控制列表 ACL (Access Control List). 节点都支持以下几种权限:
- CREATE: 可以在这个节点下创建一个子节点
- READ: 可以读取这个节点的数据
- WRITE: 可以设置这个节点的数据
- DELETE: 可以删除这个节点下的子节点
- ADMIN: 可以修改这个节点的权限
注意 ZooKeeper 的权限仅作用于当前节点, 并不会影响其子节点. 也就是说可以将权限设置成 /app 可读但是 /app/status 不可读.
不同于 UNIX 文件系统中 user, group, other 三种权限作用域, ZooKeeper 的每个节点都有一个访问者 id 到访问权限的映射列表. 每个 id 的格式为 scheme:expression, scheme 为这个 id 的方案, expression 则具体定义这个 id. 例如 ip:172.16.16.1 就是一个 id, 它的方案为 IP, 标识 IP 地址为 172.16.16.1 的用户. ZooKeeper 权限有以下几种方案:
- world: 代表所有用户.
- auth: 代表当前用户. 当一个用户想创建一个仅能被它自己访问的节点时就可以使用 auth 代表它自己.
- digest: 使用字符串
username:password生成的 MD5 哈希作为 id. - ip: 使用 IP 地址作为 id.
- x509: 使用 x509 证书作为 id.
持久化
ZooKeeper 会将整个树状结构的数据都存储在内存中. 然而仅存储在内存中是不够的, 为了防止数据丢失, 还必须持久化在硬盘上. ZooKeeper 的做法有些类似于 Redis 的 AOF: 所有的更新操作都会实时记录在一个日志文件中; 当这个日志文件变得足够大了, ZooKeeper 就会生成一个包含当前所有 znode 数据的快照文件, 然后再创建一个新的日志文件, 之后的操作事务就会记录在这个新的日志文件中. 在生成快照的过程中产生的操作事务仍然记录在旧的日志文件中. 需要说明的是 ZooKeeper 不会自动清理旧的日志文件和快照文件, 这需要管理者定期手动清理.
集群部署
ZooKeeper 的一个重要特性就是支持集群部署, 称为复制模式 (replicated mode), 因此健壮性很高.
ZooKeeper 可以配置为多台机器协同工作, 这些机器整体作为一个 ZooKeeper 服务. 数据会自动在这些服务器之间同步, 客户端可连接其中的任意一台服务器. 如果客户端连接的服务器宕机, 它可以立刻转而连接另外的服务器, 而保持原有的会话状态. ZooKeeper 保证只要大部分服务器可用, 整个 ZooKeeper 服务就是可用的.
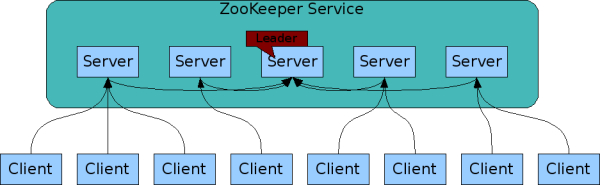
ZooKeeper 要求一半以上的服务器可用, 整个服务就可用, 因此 ZooKeeper 服务器的数量通常是奇数个. 3 台机器可承受 1 台机器故障, 5 台机器可承受 2 台机器故障; 然而 4 台机器 只能承受 1 台机器故障, 2 台机器无法承受机器故障.
由于 ZooKeeper 的服务器之间要互相同步数据, 因此 znode 中不宜存储过大的数据, 一般大小在字节到千字节到范围内. 过大的数据会导致存取效率低下.
一致性保证
尽管 ZooKeeper 是分布式的, 它仍然提供了一系列的一致性保证:
- 顺序一致性: 来自客户端的更新请求会按照发送到顺序依次执行.
- 原子性: 更新要么成功, 要么失败. 不会有中间状态.
- 单系统映像: 无论客户端连接 ZooKeeper 服务中的哪个服务器, 它看到的东西都是一样的. 即使客户端由于一些故障改变了连接的服务器, 只要在同一个会话中, 它看到的数据也是最新的.
- 可靠性: 一旦应用了一次更新操作, 就会保持这个状态直到下次更新覆盖它. 这个保证有两个结果:
- 一旦客户端的操作返回了成功, 就确保这次操作的更新已经生效了 (这也被称为单调性).
- 即使出现服务器宕机, 也不会造成任何数据回滚.
- 及时性: 整个系统中客户端看到的东西能保证在一定的时间范围 (大约几十秒) 内是最新的. 可通过 sync 操作等待当前数据更到最新.
安装
二进制安装
ZooKeeper 使用 Java 编写, 安装前先确保你的机器上有 Java 环境.
从发布页下载 ZooKeeper 的二进制发布版. 下载到到压缩包到文件名一般是 apache-zookeeper-X.X.X-bin.tar.gz, 解压之后的目录是这样的:
1 | |
然后执行 bin/zkServer.sh version, 看到 ZooKeeper 的版本信息就说明安装成功了:
1 | |
源码安装
也可以使用源码自行编译. 当然, 这要求你的机器已经安装好 JDK. 此外还需要安装 Maven, 一种 Java 项目的构建工具.
从发布页下载 ZooKeeper 的源码发布版. 下载到到压缩包到文件名一般是 apache-zookeeper-X.X.X.tar.gz, 解压后执行 mvn package 进行编译 (或者使用 mvn package -Dmaven.test.skip=true 跳过单元测试). 一切顺利的话, 同样执行 bin/zkServer.sh version 就能看到版本信息了.`
使用
单点部署
新建一个文件 conf/zoo.cfg, 内容如下:
1 | |
这是一个最简单的配置. 它有三个字段:
tickTime: 一个 tick 的毫秒数, 用作 ZooKeeper 基本时间单位. 心跳和最小会话超时时间为两个 tick.dataDir: 数据存储路径, 包括快照和事务日志 (除非另有指定).clientPort: 开放给客户端的端口.
我们执行 bin/zkServer.sh start 启动服务器:
1 | |
看到如上的输出便说明 ZooKeeper 启动成功了.
接下来我们可以启动客户端连接 ZooKeeper 了. 执行 bin/zkCli.sh -server 127.0.0.1:2181 运行客户端, 连接成功后就能进入客户端交互界面了:
1 | |
我们可以键入 help 查看有哪些命令. 现在我们执行 ls 查看根结点下有哪些子节点:
1 | |
根结点下默认会有一个 zookeeper 节点. 接下来我们可以尝试执行 create 创建一个节点:
1 | |
创建成功后, 再执行 ls / 就能再根结点下看到我们刚创建的节点了. 我们还能执行 get 获取节点的内容. 接着我们执行 set 修改节点的内容:
1 | |
多点部署
为了对抗单点失效, 在生产环境中我们通常采用多点部署的方式. 多点部署的配置如下:
1 | |
这个配置新增了几个字段:
initLimit: 连接上 leader 节点的时间限制, 单位是 tick.syncLimit: 与 leader 节点同步数据的时间限制, 单位是 tick.server.X: 各个节点的地址和端口,X为节点的 ID. 为了让每个节点知道自己的 ID 是多少, 需要在 dataDir 下创建一个名为myid的文件, 内容为当前节点的 ID. 每个节点会指定两个端口, 第一个为这个节点作为 leader 时开放的端口, 第二个为 leader 选举时使用的端口.
在多台机器上部署 ZooKeeper, 不同实例的配置文件可以是一样的; 不过在测试环境下, 用一台机器运行多个 ZooKeeper, 由于存在端口冲突和路径冲突, 需要用到不同的配置. 因此我们的配置可能是这样的:
1 | |
注意不同实例的 dataDir 和 clientPort 要不同, 此外注意我们还修改了 server.X 的端口, 让它们不会冲突.
我们创建好这三个配置文件, 然后在每个的 dataDir 下创建对应的 myid 文件, 然后执行 bin/zkServer.sh --config CONF_DIR 启动三个 ZooKeeper 实例. 然后我们启动两个客户端连接两个不同的实例, 在其中一个上创建一些节点, 修改一些数据; 然后就能在另一个客户端上看到这些修改了.
我们还可以告诉客户端所有的实例, 此时客户端会选择连接其中一个:
1 | |
可以看到客户端此时连上了 127.0.0.1:2183. 如果这时我们将这个实例停止, 客户端就会尝试连接其他其他的实例继续工作:
1 | |
可以看到连接断开时客户端抛出了一个异常; 但是随后马上又连接上了另一个实例. 因此, 多点部署的 ZooKeeper 能够有效对抗单点失效, 有很强的高可用性.
编程
ZooKeeper 支持 Java 和 C 的编程接口. 这里我们介绍 C 编程接口.
安装环境
安装 ZooKeeper 的 C 开发环境需要先下载并编译 ZooKeeper 的源码发行版, 这个过程前面讲安装 ZooKeeper 的时候有介绍. 之后进入目录 zookeeper-client/zookeeper-client-c, 这里包含了 ZooKeeper C API 的源码. 为了编译这些源码, 我们需要安装 autoconf, automake 和 libtool, 此外还需要安装一个 C++ 单元测试库 cppnuit. 准备就绪后执行 autoreconf -if 生成 configure 脚本.
注意: 如果 cppunit 没有安装在标准路径下 (如使用源码编译安装或者使用 brew 安装), 会导致 autoconf 找不到 cppunit. 这必须手动指定
cppunit.m4文件所在的目录. 例如cppunit.m4的路径为/usr/local/share/aclocal/cppunit.m4, 就应执行ACLOCAL="aclocal -I /usr/local/share/aclocal" autoreconf -if. 但是最新版的 cppunit 已经不会自动安装cppunit.m4文件了, 这就需要手动将这个文件拷贝到相应的路径下.
得到 configure 脚本之后再依次执行 ./configure, make 和 make install 即可.
使用
环境安装成功后就可以开始编程了. ZooKeeper 官方并没有提供 C API 的文档, 不过 zookeeper.h 中有很详细的注释, 相当于文档.
ZooKeeper 的 API 有单线程模式和多线程模式两种, 支持同步接口和异步接口. 同步接口仅在多线程模式下适用. 以下是它们的特点:
| 多线程 | 单线程 | |
|---|---|---|
| 异步接口 | 通过回调函数告知结果, 回调函数运行在子线程 | 通过回调函数告知结果, 回调函数运行在主线程; 需由使用者驱动事件循环 |
| 同步接口 | 直接返回结果 | - |
同步接口
同步接口比较简单, 首先调用 zookeeper_init 创建 ZooKeeper 句柄, 连接上 ZooKeeper 服务器; 然后就可以调用相应的接口执行相应的操作了, 操作的结果也是直接返回的. 例如 zoo_exists 是 exists 操作, zoo_get 是 get 操作等.
下面的例子展示了使用同步接口执行 ZooKeeper 的 exists, create, get children, set 和 get 操作:
1 | |
编译并运行:
1 | |
注意我们使用 -lzookeeper_mt 链接 ZooKeeper 的多线程动态链接库. 稍后可以看到还可以使用 -lzookeeper_st 链接单线程动态链接库.
多线程异步
异步接口一般以 zoo_a 开头, 如 zoo_aexists, zoo_aget 等. 异步接口的使用也并不复杂, 与同步接口不同的是调用者要传入一个回调函数, 操作完成时操作结果会在回调函数中告知.
1 | |
上面的代码同样依次执行了 exists, create, get children, set 和 get 操作. 由于操作是异步的, 因此要在回调函数处理结果并执行下一步操作. 注意第五步调用的是 zoo_awget, 获取一个节点的内容同时观察该节点. 这个函数传入两个回调函数, 一个是观察回调, 当节点改变时会被调用; 另一个是结果回调, get 执行完毕回调它以告知结果. 最后还调用了 getchar 阻塞 main 函数以等待异步操作结束.
编译并运行:
1 | |
可以看到回调函数跑在子线程中. 如果回调函数中访问了临界资源, 就要加锁.
这个时候程序还没退出, 别急着关闭它: 打开 ZooKeeper 客户端, 修改 /data 的值, 就能看到程序检测到 /data 节点的内容发生了改变:
1 | |
单线程异步
单线程异步接口的使用与多线程异步是一致的, 不同的是需要我们驱动 ZooKeeper 的事件循环. 为此 ZooKeeper 提供了两个接口, zookeeper_interest 和 zookeeper_process. zookeeper_interest 会返回当前 ZooKeeper 期望监听的文件和事件, 例如它会告诉调用者期望监听某个文件的可读事件. 之后我们就可以使用 select(2) 或者 epoll(7) 之类的方式监听文件. 当文件对应的事件触发后, 我们就可以调用 zookeeper_process 告诉 ZooKeeper 对应的事件触发了. 这可以嵌入到程序的事件循环中.
我们将上面多线程异步代码的 getchar(); 替换成如下的代码就可以了:
1 | |
注意上面的代码还监听了标准输入, 一旦检测到标准输入就 break 跳出主循环, 跟前面的 getchar() 效果一样.
我们再编译运行, 注意这里使用 -lzookeeper_st 链接单线程库.
1 | |
可以看到这次回调函数是运行在主线程中的.
应用
ZooKeeper 有很多种应用. 除了简单地作为存储服务使用外, 它还有以下几种重要应用:
互斥锁
在任务异步执行的分布式系统中, 当多个进程需要同时访问临界资源时, 我们常常需要对这个资源加锁. 使用 ZooKeeper 很容易实现一个用于分布式系统的互斥锁. 实现互斥锁需要用到 ZooKeeper 节点的两种特殊性质:
- 临时节点 (Ephemeral Nodes): 创建节点时可以指定一个节点是临时节点. 临时节点会在会话结束时自动删除. 互斥锁使用临时节点可以保证当加锁的服务 crash 后自动释放锁.
- 序列节点 (Sequence Nodes): 如果创建节点的时候指定它为序列节点, ZooKeeper 就会在节点路径末尾追加一段十位数字的序列号, 如
0000000001. 序列号是顺序递增的, 不会有重复.
具体的做法是, 首先我们指定一个路径为锁节点, 如 /lock. 如果要得到锁, 就执行以下操作:
- 执行 create 操作在锁节点下创建一个临时序列节点 L. 例如调用
zoo_acreate创建一个前缀路径为/lock/s-的节点, 参数mode传ZOO_EPHEMERAL_SEQUENTIAL指定它为临时序列节点. 创建成功时就会在回调函数中告诉我们节点的完整路径为/lock/s-0000000001. - 执行 get children 操作获取锁节点的所有子节点, 从中找出序列号最小的节点.
- 如果序列号最小的节点就是我们刚才创建的那个节点 L, 我们就得到了这个锁, 流程结束.
- 否则, 对序列号仅次于 L 的节点执行 exists, 并设置观察.
- 如果 exists 操作的结果是不存在, 则跳转到第 2 步; 否则待观察回调触发后, 再跳转到第 2 步.
如果要解除锁, 则只需删除 L 节点即可.
可以看到, 如果创建的一个序列号最小的节点, 就得到了这个锁, 这就保证了同一时间只有一个进程能够获得锁. 同时对于序列号不是最小的节点, 它会监听序列号仅次于它的节点的存在状态, 一旦状态发生变化 (i.e. 被删除了), 就会再次检测自己是不是最小的节点. 这就实现了锁的抢占与等待.
这种实现有几个好处:
- 每个节点最多只会监听一个节点, 也就是序列号仅次于它的节点. 这就避免了惊群效应: 锁的解除最多只会唤醒一个节点.
- 不需要做任何轮询.
- 很容易查看锁的状态, 如有多少个进程在等待锁; 也很容易手动干预, 调试锁问题等.
这种实现还有一个问题: 如果在第 1 步创建临时序列节点时, ZooKeeper 创建节点成功, 但是在准备返回应答时 crash 了, 或者网络断了. 此时节点已经创建成功, 而调用者却不知道, 也不知道节点的完整路径. 当调用者重连之后, 它只能再次执行第 1 步重新创建节点. 由于会话并没有结束, 节点也不会被删除, 这个时候锁节点下就有一个无人管理的子节点, 这会导致死锁.
解决办法是, 在创建节点的时候生成一个 GUID, 然后让节点的路径前缀带上这个 GUID, 如 /lock/BD531351-A828-80EA-5CE2-B3D4213042A8-. 这样, 如果创建节点时出现异常, 调用者在重连之后可以通过 GUID 判断第 1 步节点是否创建成功. 如果创建成功, 就可以继续第 2 步. 这就解决了这个问题.
读写锁
在一些读操作多于写操作的场景下, 我们常常用到读写锁, 可以改善锁的性能. 读写锁允许多个进程同时获得读锁, 但是同时只能有一个进程获得写锁, 且写锁与读锁不能被同时获得. ZooKeeper 也能实现分布式读写锁, 只需要在互斥锁的基础上做一些改动.
如果要获得写锁, 则执行:
- 在锁节点下创建一个临时序列节点 W, 路径前缀为
/lock/GUID-write-, 路径中包含生成的 GUID. - 执行 get children 操作获取锁节点的所有子节点.
- 检测是否有序列号比 W 小的节点. 如果没有, 我们就得到了写锁, 流程结束.
- 否则对序列号仅次于 W 的节点执行 exists 操作并设置观察.
- 如果 exists 操作的结果是不存在, 则跳转到第 2 步; 否则待观察回调触发后, 再跳转到第 2 步.
如果要获取读锁, 则执行:
- 在锁节点下创建一个临时序列节点 R, 路径前缀为
/lock/GUID-read-, 路径中包含生成的 GUID. - 执行 get children 操作获取锁节点的所有子节点.
- 检测是否有序列号比 R 小且路径带有
write-的节点. 如果没有, 我们就得到了读锁, 流程结束. - 否则对序列号仅次于 R 且路径带有
write-的节点执行 exists 操作并设置观察. - 如果 exists 操作的结果是不存在, 则跳转到第 2 步; 否则待观察回调触发后, 再跳转到第 2 步.
以上的步骤满足了读写锁的性质: 读锁只与写锁互斥, 写锁与所有的锁互斥. 解除锁的操作与互斥锁相同, 直接删除第 1 步创建的节点即可.
队列
利用序列节点的性质我们还能实现队列. 这很容易实现一个生产者-消费者模型:
- 指定一个路径为队列节点. 如
/queue. - 对于生产者, 它需要将消息入队. 这只需在队列节点下创建一个序列节点, 节点的内容为消息内容.
- 对于消费者, 它会不断地处理队列中的消息, 直到队列为空则等待. 它需要:
- 对队列节点执行 get children 并设置观察, 然后根据节点序号从小到达依次处理.
- 当有新节点创建时, 会触发观察回调. 跳转到第 1 步重复执行即可.
二阶段提交 (Two-phased Commit)
在分布式开发中, 我们常常会遇到这样的场景: 一个过程的若干操作需要在不同的进程上执行, 而这些操作都有可能失败; 假设在 A 进程上执行的操作成功了, 数据已经修改了, 但是在 B 进程上执行的操作却失败了. 那 A 进程上已修改的数据该怎么办呢? 这就无法保证过程中数据的一致性了. 为了解决这个问题, 人们就提出了二阶段提交.
在二阶段提交中, 引入了一个进程专门协调处理执行任务的进程, 称为协调者 (coordinator), 而其他执行任务的节点称为参与者 (participant). 执行任务时协调者告诉各个参与者执行相应的任务, 参与者执行结束后会告诉协调者是否执行成功, 此时参与者并不会 commit 修改, 而是暂时挂起. 当协调者发现所有参与者都执行成功时, 就会告诉各个参与者 commit 修改, 否则告诉所有参与者 rollback 修改. 这样就保证的整个过程的一致性.

我们可以使用 ZooKeeper 实现二阶段提交. 具体有以下几步:
- 协调者创建一个事务节点, 如
/tx, 再在其下为每个参与者创建一个子节点, 如/tx/p_i. - 协调者通知所有的参与者开始执行任务.
- 参与者执行 get children 获取事务节点下的所有子节点, 并监听它们的内容变化.
- 若参与者的任务执行成功, 则将自己节点的内容置为
yes; 否则内容置为no. - 参与者的观察回调被触发. 如果发现所有参与者节点内容都为
yes, 则 commit 修改, 否则 rollback 修改.
这样协调者只需创建节点和通知参与者即可.
参考资料: