使用 gperftools 分析程序性能
gperftools 是谷歌推出的一套非常强大的性能分析工具集. 它主要有这三个功能:
- 分析 CPU 性能, 能够统计出一段时间内各个函数的执行时间, 帮助我们找出耗时的代码;
- 分析内存占用情况, 能够统计出某一时刻各个函数分配的内存大小, 帮助我们找出内存占用高的代码, 也能帮助我们定位内存泄露;
- 自动检查内存泄露.
gperftools 还包含一个高性能内存分配器 tcmalloc, 我们可以用它代替 glibc 的 ptmalloc. tcmalloc 自带统计功能, 内存分析和检查内存泄露就靠它.
本文介绍 gperftools 在 Linux 下的一些常见的用法. 如果你需要使用 gperftools 分析 Linux (服务器) 程序, 这篇文章可以当作一个 Quick Start.
编译与安装
到 gperftools 的 release 页面下载稳定版本. 如果 Linux 是 64 位版本, 则 gperftools 建议安装 libunwind. 这一般使用 yum 或 apt 直接安装即可. 解压后直接执行
1 | |
这会安装 libprofiler.so 和 libtcmalloc.so 等库文件, 性能报告生成工具 pprof, 还有一堆头文件等.
CPU 性能分析
为了使用 CPU 性能分析功能, 我们需要将共享库 libprofiler 链接进可执行文件. gperftools 推荐在 (编译) 链接的时候加上 -lprofiler 选项, 例如
1 | |
这样并不会让程序在运行时开启性能收集, 这只是插入了 profiler 的代码. 如果不开启, 程序不会有什么影响. 因此 gperftools 推荐总是在开发环境加上 -lprofiler, 在谷歌他们就是这么做的.
另一种可选的方式是使用 LD_PRELOAD 环境变量将 libprofiler.so hook 进程序. 这种方法不需要重新编译程序, 只需要在程序运行的时候加上环境变量即可, 例如
1 | |
这样 ./factorio 运行的时候同样带有 profiler 的代码.
开启性能收集
只需要将环境变量 CPUPROFILE 设置为性能收集结果的文件路径即可开启性能收集. 例如
1 | |
这样程序自运行开始就会开启性能收集, 直到程序停止. 性能收集的结果会写入 CPUPROFILE 指定的文件. 如果程序调用了 fork(2) 创建了子进程, 那么子进程也会开启性能收集. 为了与父进程区分开, 收集结果的文件名会拼上进程 ID.
很多情况下我们并不希望全程收集性能数据. 并且在多进程的场景下, 我们也希望收集指定 ID 的进程. gperftools 支持使用使用信号控制性能收集开关: 我们可以使用环境变量 CPUPROFILESIGNAL 指定开关信号. 程序首次收到指定信号的时候会开启性能收集, 再次收到就会关闭. 例如
1 | |
假设 server 的进程 ID 为 10191, 那么只需要执行 kill -12 10191 即可开启性能收集; 再次执行 kill -12 10191 就会停止, 并将收集结果写入文件.
gperftools 的默认收集频率是每秒 100 次. 我们也可以使用环境变量 CPUPROFILE_FREQUENCY 指定收集频率. 例如
1 | |
导出分析报告
在 Linux 服务器上我们通常使用 pprof 导出 pdf 格式的分析报告. pprof 依赖 dot 和 ps2pdf 绘图和生成 pdf, 因此我们需要先安装它们
1 | |
还是上面 ./server 的例子, 使用如下命令即可导出 pdf
1 | |
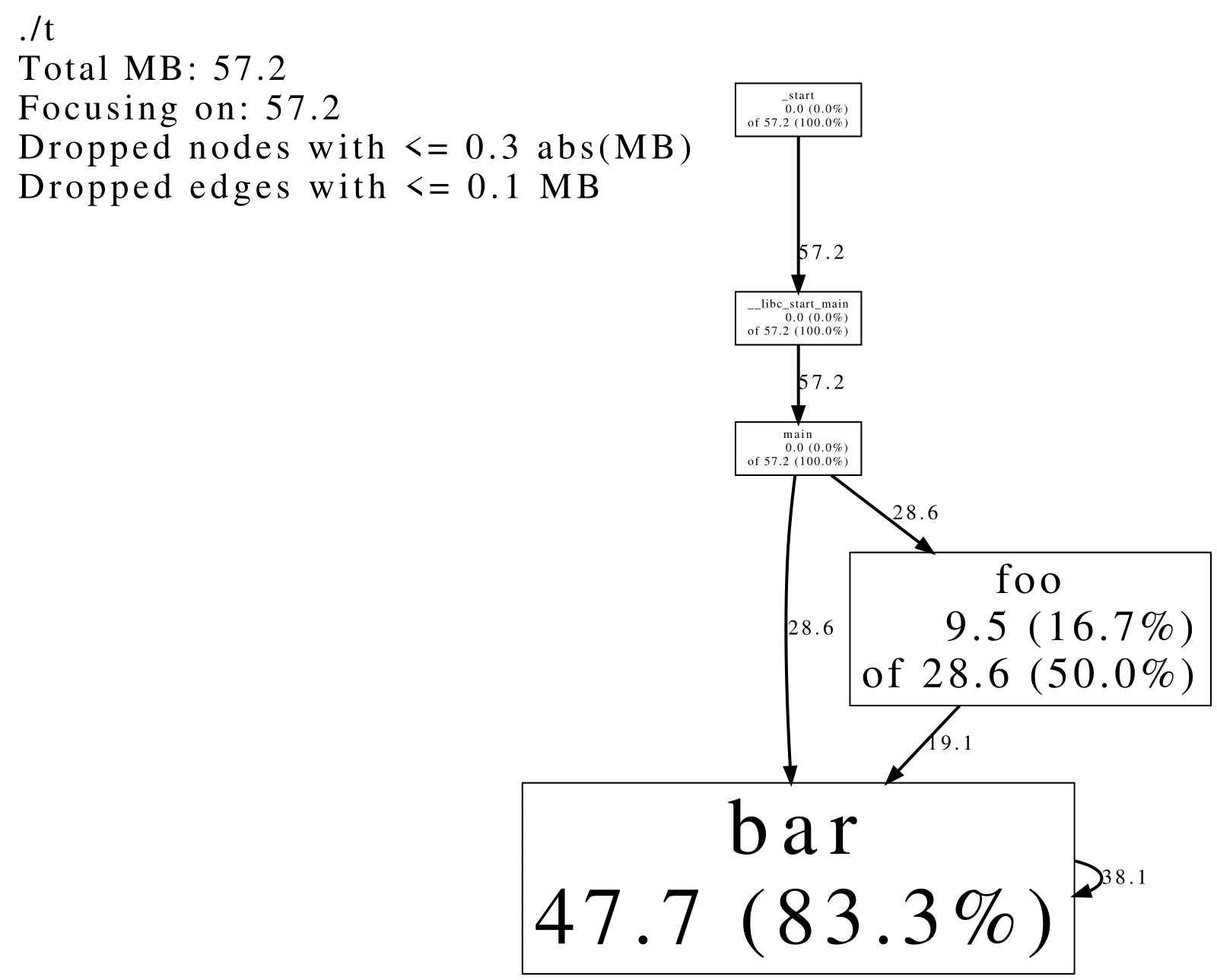
我们就能得到类似这样的分析报告:

报告会显示函数之间的调用关系, 以及每个函数所占用的时间. 图中每个节点代表一个函数, 每条边代表它们之间的调用关系. 每个节点都有这样的格式
1 | |
其中 cumulative 表示这个函数占用的总时间, 也就是这个函数自身的代码占用的时间, 加上调用其他函数占用的时间. local 则表示这个函数自身代码占用的时间. 每条边上的数字表示调用所指向函数占用的总时间. 也就是说, cumulative 等于这个节点所有 “入度” 之和; local 加上这个节点所有 “出度” 之和等于 cumulative. 节点越大, 这个函数的 loacl 时间就越长.
时间的单位取决于收集频率. 如果是默认的每秒 100 次, 则单位大约是 10 毫秒. 在上图的例子中, test_main_thread 的总执行时间约为 2000 毫秒, 其中约有 1550 毫秒是该函数本身代码占用的, 400 毫秒是其调用 snprintf 占用的, 50 毫秒是其调用 vsnprintf 占用的.
pprof 导出报告时会省略掉一些耗时较小的节点和边. 我们也可以通过参数指定省略的阈值.
--nodecount=<n>: 只显示最耗时的前n个节点, 默认为 80.--nodefraction=<f>: 只显示耗时占比不小于f的节点, 默认为 0.005 (也就是说耗时占比不到 0.5% 的节点会被丢弃). 如果同时设置了--nodecount和--nodefraction, 则只有同时满足这两个条件的节点才会保留.--edgefraction=<f>: 只显示耗时占比不小于f的边, 默认为 0.001.
内存分析
为了使用内存分析功能, 我们需要共享库 libtcmalloc 链接进可执行文件. 与 libprofiler 类似, gperftools 推荐使用 -ltcmalloc 链接选项将共享库链接进可执行文件. 如果你不能重新编译程序, 也可以使用 LD_PRELOAD. 同样地, 链接共享库只是插入了 tcmalloc 的代码, 并不会开启内存统计.
开启内存统计
只需要将环境变量 HEAPPROFILE 设置为内存统计结果的文件路径即可开启内存统计. 例如
1 | |
内存统计与性能收集不同. 性能收集是收集一段时间内各个函数所占用的时间, 而内存既有分配又有释放. 因此内存统计是统计特定时刻各个函数占用的内存大小.
gperftools 每过一段时间就会统计当前程序的内存占用情况, 生成一个结果文件. 如上面的例子, 环境变量 HEAPPROFILE=server, 则会生成这样一系列的结果文件
1 | |
gperftools 的默认统计规则是, 程序每分配 1 GB, 或每占用 100 MB, 统计一次. 这个行为也可以通过环境变量控制
HEAP_PROFILE_ALLOCATION_INTERVAL: 每分配多少字节的内存统计一次. 默认为 1073741824 (1 GB).HEAP_PROFILE_INUSE_INTERVAL: 每占用多少字节的内存统计一次. 默认为 104857600 (100 MB).HEAP_PROFILE_TIME_INTERVAL: 每隔多少秒统计一次. 默认为 0.HEAPPROFILESIGNAL: 每当收到指定信号统计一次.
导出分析报告
我们同样使用 pprof 导出内存分析报告. 记得安装好 dot 和 ps2pdf.
1 | |
这能得到类似这样的分析报告:
与性能报告类似, 内存报告同样显示各个函数的调用关系; 不同的是, 这里展示的是每个函数占用的内存而不是时间. 每个节点上同样有 local of cumulative 这样的格式, local 为函数自身代码占用的内存大小, cumulative 为函数自身以及调用其他函数占用的内存大小. 每条边上的数字表示有多少内存是由于调用所指向函数而分配的.
内存分析报告清晰地显示每个函数占用的内存, 这些数据能够帮助我们检查内存泄露. 例如, 通过对比各个时间点函数占用的内存大小, 如果一个函数占用的内存一直在增长, 意味着这个函数很有可能有内存泄露. pprof 提供了 --base 参数帮助我们对比两个时间点的内存变化
1 | |
这样报告显示的内存是 server.0003.heap 记录的内存占用减去 server.0001.heap 记录的内存占用.
内存泄露检查
除了根据内存分析报告手动检查内存泄露, gperftools 还提供了自动的内存泄露检查工具. 检查工具也集成在 tcmalloc 里, 我们同样需要将 libtcmalloc 链接进程序. 检查工具会在程序开始时统计内存的分配和释放, 并且在程序结束前分析内存泄露情况. 设置环境变量 HEAPCHECK=normal 即可开启内存泄露检查
1 | |
可以得到类似这样的输出
1 | |
结果显示有 6 个对象泄露了, 并且展示每个对象的大小. 最后提示我们可以使用 pprof 命令得到更详细的报告. 在服务器上我们无法使用 --gv 选项, 我们可以使用 --pdf 导出 pdf 作为替代:
1 | |
可以得到类似这样的结果:
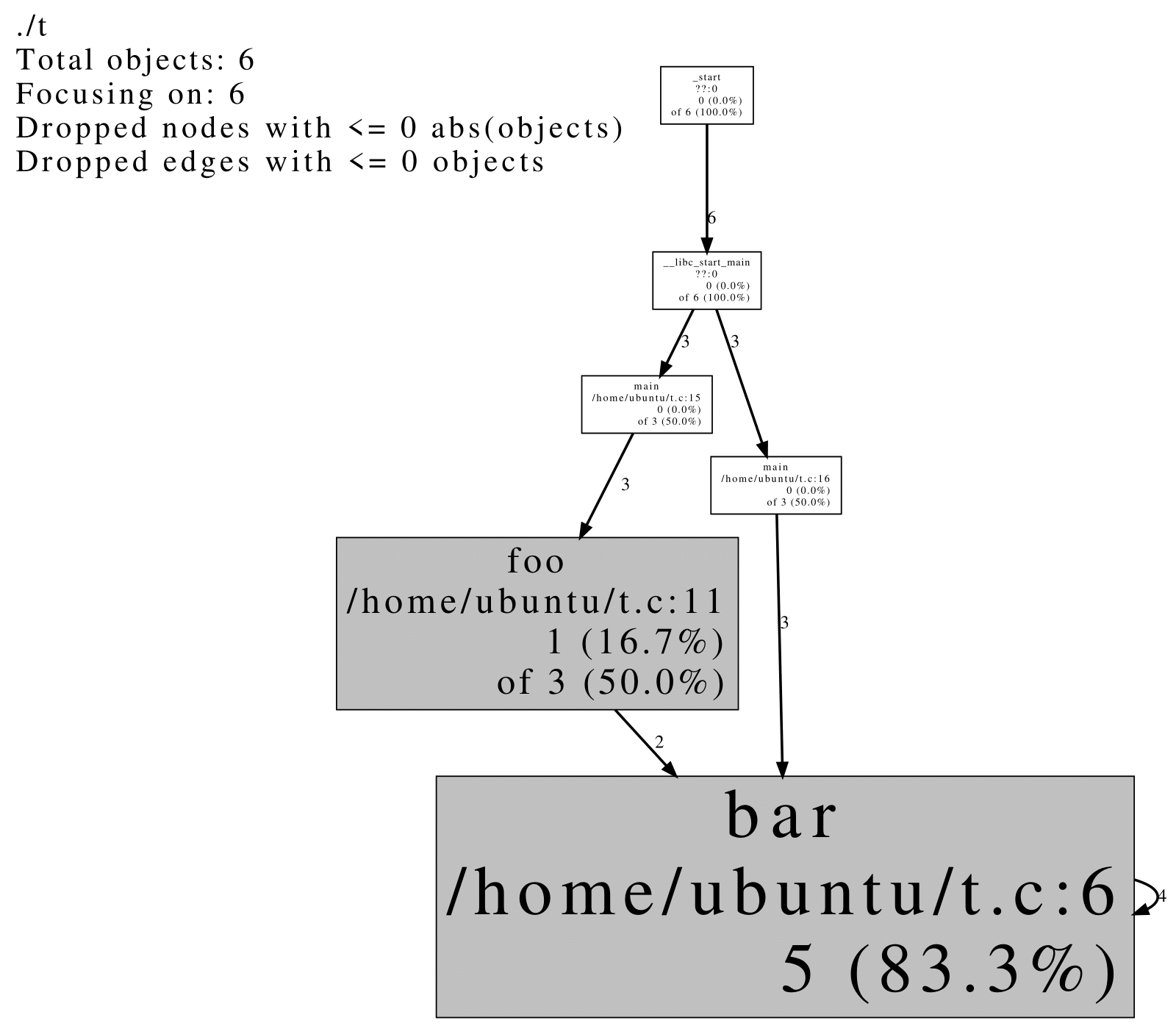
结果同样为函数调用关系图, 每个节点上的 local of cumulative 指出泄露了多少个对象. local 为这个函数自身代码导致泄露的对象数量, cumulative 为 local 加上调用其他函数导致泄露的对象数量. 每条边上的数字指出有多少对象的泄露是调用所指向函数导致的.
内存泄露的检测方法
当设置 HEAPCHECK=normal 时 gperftools 的内存检查工具检测的是泄露的对象而不是泄露的内存. 分配了但未释放的内存不一定被认为是泄露的, 只有那些无法被访问到的对象才会被认为是泄露的. gperftools 将内存中正确对齐的字节序列视为指针, 检查堆中分配的对象有没有被这些 “指针” 指向. 如果没有, 则这个对象是泄露的. 例如下列代码不会报告内存泄露, 尽管存在未被释放的内存.
1 | |
因此内存泄露检查不能保证 100% 准确. 此外, 有可能内存中某些字节序列的值恰好等于某个分配的对象, 虽然这种概率很低, 但是如果这个对象恰好泄露了, gperftools 是检测不到的.
虽然 normal 是最常用的, 我们也可以将 HEAPCHECK 设置成其他值以修改内存泄露的检测方法.
minimal: 尽可能晚地开始内存泄露统计, 意味着一些初始化时泄露的内存 (例如全局对象的构造函数) 不会被检测出来.normal: 最常用的模式, 严格度介于minimal和strict之间.strict: 与minimal相反, 引入一些额外的检查, 确保初始化时泄露的内存都能够检测出来.draconian: 同样确保能检测到初始化时泄露的内存, 但是不使用前面介绍的机制检测泄露的对象, 而是直接检测泄露的内存. 任何在退出时未被释放的内存都会被报告内存泄露.
扩展阅读
gperftools 还有一些更高级的用法, 例如我们可以通过 gperftools 提供的编程借口控制何时开启和关闭统计, 或者忽略某些代码的内存泄露等. 这可以帮助我们更有针对性地分析程序性能. 开启收集和统计时, gperftools 还支持一些环境变量可以更精准地控制其行为. 导出报告时, pprof 支持一些高级参数, 例如专注于某些特定的函数, 或者忽略某些特定的函数; 导出不同格式的报告等. 如果需要了解这些用法, 可以参阅 gperftools 的文档, 它们在 gperftools/docs 目录下.