C++ 实现无锁队列
前一篇文章中我们讨论了 C++ 中原子变量的内存顺序, 现在我们来看看原子变量和内存顺序的应用 – 无锁队列. 本文介绍单写单读和多写多读的无锁队列的简单实现, 从中可以看到无锁数据结构设计的一些基本思路.
何谓无锁
为了实现一个线程安全的数据结构, 最简单的方法就是加锁. 对于队列来说, 应该对入队和出队操作加锁.
1 | |
这样的队列的问题是, 同一时间只能有一个线程执行入队和出队操作, 这样队列的操作实际是串行化的. 如果有多个线程同时访问同一个队列, 这个队列可能会成为并发的瓶颈. 为了解决这个问题, 在一些场景下我们可以考虑使用无锁队列.
无锁数据接口可以分为三类:
- nonblocking 结构
- 使用自旋锁而不是互斥量, 不会出现上下文切换.
- 不能算是无锁 (lock-free), 它并不允许并发访问, 同样存在操作串行化的问题.
- lock-free 结构
- 精心设计的操作, 通过 CAS (compare and swap) 原子操作实现并发访问. 多个线程可以同时访问.
- 存在类似自旋锁的循环, 需要在循环中检查和等待.
- wait-free 结构
- 不存在类似自旋锁的循环, 操作只需要执行确定数量的指令.
下面我们介绍几种简单的无锁队列的实现.
单写单读的队列
单写单读的队列比较简单, 这里我们使用循环队列实现. 如下图所示, 队列维护两个指针 head 和 tail, 分别指向队首和队尾. tail 始终指向 dummy 节点, 这样 tail == head 表示队列为空, (tail + 1) % Cap == head 表示队列已满, 不用维护 size 成员.

入队的时候移动 tail 指针, 而出队的时候移动 head 指针, 两个操作并无冲突. 不过, 出队前需要读取 tail 指针, 判断 tail != head 确认队列不为空; 同理入队时也要判断 (tail + 1) % Cap != head 以确认队列不满. 由于存在多个线程读写这两个指针, 因此它们都应该是原子变量.
此外, 由于两个操作在不同线程中执行, 我们还需考虑内存顺序. 如果初始队列为空, 线程 a 先执行入队操作, 线程 b 后执行出队操作, 则线程 a 入队操作的内容要对线程 b 可见.

为了做到这一点, 需要有 a(2) “happens-before” b(3). 而 a(3) 和 b(2) 分别修改了读取了 tail, 所以应该利用原子变量同步, 使得 a(3) “synchronizes-with” b(2). 可以在 a(3) 写入 tail 的操作中使用 release, b(2) 读取 tail 的操作中使用 acquire 实现同步. 不熟悉内存顺序的同学可以参考上一篇文章.
同理, 如果初始队列满, 线程 a 先执行出队操作, 线程 b 后执行入队操作, 则线程 a 出队操作的结果要对线程 b 可见. 出队的时候需要调用出队元素的析构函数, 要保证出队元素正常销毁后才能在那个位置写入新元素, 否则会导致内存损坏. 可以在出队写入 head 的操作中使用 release, 入队读取 head 的操作中使用 acquire 实现出队 “synchronizes-with” 入队.
1 | |
这种单写单读的无锁队列的两种操作可以同时执行, 且两种操作都只需要执行确定数量的指令, 因此数据 wait-free 结构, 性能很高.
CAS 操作
CAS (compare and swap) 是一种原子操作, 在一个不可被中断的过程中执行比较和交换. C++ 的 std::atomic 中有两种 CAS 操作, compare_exchange_weak 和 compare_exchange_strong
1 | |
这两种 CAS 操作基本上是相同的: 如果原子变量与 expected 相等, 则将其赋值为 desired 并返回 true; 否则 expected 赋值成原子变量当前的值并返回 false. 下面是 compare_exchange_strong 的一个伪实现
1 | |
当然实际的实现不可能是这样的. 在 x86 下 compare_exchange_* 会被编译成一条 cmpxchgl 指令, 因此操作是原子且无锁的.
1 | |
x86-64 下 -O2 编译成:
1 | |
compare_exchange_weak 和 compare_exchange_strong 的区别在于, compare_exchange_weak 有可能在当前值与 expected 相等时仍然不执行交换并返回 false; compare_exchange_strong 则不会有这个问题. weak 版本能让编译器在一些平台下生成一些更优的代码, 在 x86 下是没区别的.
compare_exchange_* 支持指定两个内存顺序: 成功时的内存顺序和失败时的内存顺序.
1 | |
我们可以利用 CAS 操作实现很多无锁数据结构. 下面我们来看如何实现多写多读的队列.
多写多读的队列
为了说明前面实现的单写单读队列无法执行多写多读, 我们来看一个例子.
1 | |
假设有两个线程 a 和 b 同时调用 pop, 执行顺序是 a(1), b(1), b(2) a(2). 这种情况下, 线程 a 和线程 b 都读到相同的 head 指针, 存储在变量 h 中. 当 a(2) 尝试读取 data[h] 时, 其中的数据已经在 b(2) 中被 move 走了. 因此这样的队列不允许多个线程同时执行 pop 操作.
解决抢占问题
可以看到, 整个 pop 函数是一个非原子过程, 一旦这个过程别其他线程抢占, 就会出问题. 如何解决这个问题呢? 在无锁数据结构中, 一种常用的做法是不断重试. 具体的做法是, 在非原子过程的最后一步设计一个 CAS 操作, 如果过程被其他线程抢占, 则 CAS 操作失败, 并重新执行整个过程. 否则 CAS 操作成功, 完成整个过程的最后一步.
1 | |
首先注意到我们不再使用 std::move 和 allocator::destroy, 而是直接复制, 使得循环体内的操作不会修改队列本身. (3) 是整个过程的最后一步, 也是唯一会修改队列的一步, 我们使用了一个 CAS 操作. 只有当 head 的值等于第 (1) 步获取的值的时候, 才会移动 head 指针, 并且返回 true 跳出循环; 否则就不断重试.
这样如果多个线程并发执行 pop, 则只有成功执行 (3) 的线程被视为成功执行了整个过程, 其它的线程都会因为被抢占, 导致执行 (3) 的时候 head 被修改, 因而与局部变量 h 不相等, 导致 CAS 操作失败. 这样它们就要重试整个过程.
类似的思路也可以用在 push 上. 看看如果我们用同样的方式修改 push 会怎样:
1 | |
与 pop 操作不同, push 操作的第 (2) 步需要对 data[t] 赋值, 导致循环体内的操作会修改队列. 假设 a, b 两个线程的执行顺序是 a(1), a(2), b(1), b(2), a(3). a 可以成功执行到 (3), 但是入队的值却被 b(2) 覆盖掉了.
我们尝试将赋值操作 data[t] = val 移到循环的外面, 这样循环体内的操作就不会修改队列了. 当循环退出时, 能确保 tail 向后移动了一格, 且 t 指向 tail 移动前的位置. 这样并发的时候就不会有其他线程覆盖我们写入的值.
1 | |
但是这样做的问题是, 我们先移动 tail 指针再对 data[t] 赋值, 会导致 push 与 pop 并发不正确. 回顾下 pop 的代码:
1 | |
同样假设有两个线程 a 和 b. 假设队列初始为空
- 线程 a 调用
push, 执行 a(1), a(2).tail被更新, 然后切换到线程 b - 线程 b 调用
pop, 执行 b(4). 因为tail被更新, 因此判断队列不为空 - 执行到 b(5), 会读取到无效的值

为了实现 push 与 pop 的并发, push 对 data[t] 的写入必须 “happens-before” pop 对 data[h] 的读取. 因此这就要求 push 操作先对 data[t] 赋值, 再移动 tail 指针. 可是前面为了实现 push 与 push 的并发我们又让 push 操作先移动 tail 再对 data[t] 赋值. 如何解决这一矛盾呢?
解决办法是引入一个新的指针 write , 用于 push 与 pop 同步. 它表示 push 操作写到了哪个位置.
1 | |
push 操作的基本步骤是:
- 移动
tail; - 对
data[t]赋值,t等于tail移动前的位置; - 移动
write.write移动后等于tail.
而 pop 操作使用 write 指针判断队列中是否有元素. 因为有 (3) “synchronizes-with” (4), 所以 (2) “happens-before” (5), pop 能读到 push 写入的值. 在 push 函数中, 只有在当前的 write 等于 t 时才将 write 移动一格, 能确保最终 write 等于 tail.
这种多写多读的无锁队列的两种操作可以同时执行, 但是每种操作都有可能要重试, 因此属于 lock-free 结构.
考虑内存顺序
前面例子使用默认的内存顺序, 也就是 memory_order_seq_cst . 为了优化性能, 可以使用更宽松的内存顺序. 而要考虑内存顺序, 就要找出其中的 happens-before 的关系.
前面分析了, push 中的赋值操作 data[t] = val 要 “happens-before” pop 中的读取操作 val = data[h], 这是通过 write 原子变量实现的: push 中对 write 的修改要 “synchronizes-with” pop 中对 write 的读取. 因此 push 修改 write 的 CAS 操作应该使用 release, pop 读取 write 时则应使用 acquire.
同理, 当队列初始为满的时候, 先运行 pop 在运行 push, 要保证 pop 中的读取操作 val = data[h] “happens-before” push 中的赋值操作 data[t] = val. 这是通过 head 原子变量实现的: pop 中对 head 的修改要 “synchronizes-with” push 中对 head 的读取. 因此 pop 修改 head 的 CAS 操作应该使用 release, push 读取 head 时则应使用 acquire.
1 | |
push 与 push 并发移动 tail 指针的时候, 只影响到 tail 本身. 因此 (1) 和 (3) 对 tail 读写使用 relaxed 就可以了. 同样 push 与 push 并发移动 write 指针时, 也不需要利用它做同步, 因此 (5) 处的做法是
1 | |
成功时使用 release, 为了与 pop 同步; 而失败时使用 relaxed 就可以了.
同理, pop 与 pop 并发移动 head 时, 也影响到 head 本身. 因此 (6) 读取 head 使用 relaxed 即可. 而 (9) 处为了与 push 同步, 成功时要使用 release, 失败时使用 relaxed 即可.
优势与缺陷
优势
- 实现简单, 容易理解 (相比更复杂的链式结构)
- 无锁高并发. 虽然存在循环重试, 但是这只会在相同操作并发的时候出现. push 不会因为与 pop 并发而重试, 反之亦然.
缺陷
- 这样队列只应该存储标量, 不应该存储对象 (但是可以存储指针), 原因有两点
- pop 中会循环执行 val = data[h] , 对象的拷贝会有性能开销
- push 中执行 data[t] = val 类似, 如果拷贝时间过长, 可能会导致并发执行 push 的线程一直等待
- 如果 push 中 data[t] = val 抛出了异常, 可能会导致并发执行 push 的线程死锁
- 不能存储智能指针. 因为出队后对象仍然在 data 数组里, 并没有销毁.
- 容量是固定的, 不能动态扩容.
性能测试
设置不同的生产者和消费者线程数量, 每个生产者向依次队列里插入 10000 个元素. 下面是测试结果, “XpYc” 表示 X 个生产者 Y 个消费者. 纵坐标为耗时.
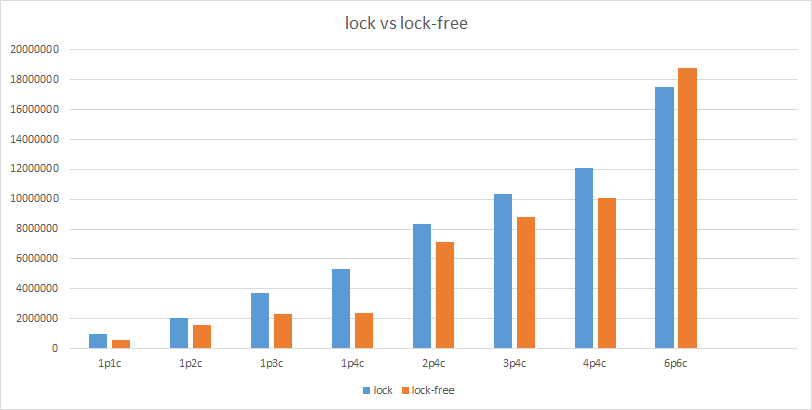
可以看到无锁队列并不总是最快, 当生产者数量增多时, 性能开始下降, 因为入队的时候需要抢占 tail 和 write. 实际应用中需要具体情况具体分析.
参考资料:
- C++ Concurrency in Action: Practical Multithreading, Anthony Williams.