Scheme 语言
我最近在读 SICP (Structure and Interpretation of Computer Programs),中文译名是《计算机程序的构造与解释》,感觉受益匪浅。我打算开个坑,总结分享一些我学到的内容。SICP 综合性非常强,内容包括函数式编程、数据结构的分层与抽象、面向对象、无限流、元循环解释器、惰性求值、非确定性编程、逻辑编程、汇编语言与机器、编译原理等等。我只能选取一个主题抛砖引玉,这个系列文章的主题是 continuation,主要内容可能包括:
- Scheme 语言
- Scheme 元循环解释器
- 神奇的
call/cc - 通过 CPS 解释器实现
call/cc - 通过 CPS 变换(也就是传说中的“王垠 40 行代码”)实现
call/cc - …
我最近已经在读最后一章了,待读完本书后再看情况更新一些内容。这些内容的基础是 Scheme 语言,我们从介绍 Scheme 语言开始。本文介绍的 Scheme 语言主要目的是让不了解 Scheme 的同学看完之后能看得懂后面几篇文章,因此不会涉及到一些很细节的内容。(特别细节的内容我也不懂,SICP 也没有很深入介绍)如果要深入了解,可以阅读相关的文档。
1 Scheme 的特性
Scheme 是一种 Lisp 的方言。而 Lisp 是世界上第二古老的语言(第一古老的是 Fortran),有着众多的方言。这些方言有着一个共同的特性——基于 S 表达式 (S-expressions)。
S 表达式可以是原子表达式 (atom) 或者列表。原子表达式可以是数字,如 1, 42, 3.14;可以是字符串,如 "hello";可以是布尔值,如 #t, #f;也可以直接是符号,如 a, if, add。而列表则是将若干个 S 表达式放在一对括号里,用空格隔开:
1 | |
下面给出了一些 S 表达式的例子:
1 | |
前三个 S 表达式都是原子表达式。(add 1 2) 是一个长度为 3 的列表,3 个元素分别是符号 add、数字 1 和数字 2。(display "Hello world") 是一个长度为 2 的列表,第一个元素是符号 display,第二个元素是字符串 "Hello world"。(list (list 1 2) (list "a" "b")) 是一个长度为 3 的列表,三个元素分别是符号 list、列表 (list 1 2)、列表 (list "a" "b")。
Scheme 全部是由 S 表达式组成的。在 Scheme 中,复合表达式的第一个元素作为表达式的类型,剩余的元素则作为表达式的参数。

表达式类型决定这个表达式的语义和参数的含义。例如 if 表达式规定有三个参数,第一个参数为条件,第二个参数为条件为真时执行的表达式,第三个参数为条件为假时执行的表达式。由于 S 表达式可以任意嵌套,因此利用它就可以构造出任意复杂的代码。下面就是一段 Scheme 代码的例子:
1 | |
可以看到 S 表达式层层嵌套,形成了一个树状结构,这其实就是语法树。也就是说这个语言实际是把语法树明确的写出来。后面我们能看到这种做法的好处:代码可以直接表示为数据结构,代码极其容易解析、编译。
2 编程环境
Scheme 作为 Lisp 的一种方言,它本身又有很多方言,例如 Chez Scheme, MIT Scheme, Racket 等。我们使用的环境是 Racket,它功能强大,易于使用。我们可以到它的官网下载最新版本。Racket 自带一个 IDE,叫 DrRacket,我们可以使用它学习编写 Scheme。
打开 DrRacket,就可以开始 Scheme 编程了。程序的第一行需要声明所使用的语言 #lang racket。编辑好了后点击 “Run” 便可执行代码。
有些同学可能不习惯这种全是括号的语言,阅读代码需要数括号,十分麻烦。但如果代码做好缩进与对齐,之间的嵌套关系是一目了然的。我们可以让参数另起一行,相对类型缩进两个空格:
1 | |
或者第一个参数与类型同行,后续参数与第一个参数对齐:
1 | |
如果第一个参数比较特殊,也可以让第一个参数与类型同行,剩余的参数另起一行,并缩进两个空格
1 | |
基本上就这三种缩进风格。使用 DrRacket 可以自动缩进;阅读代码时一般不需要关心括号,直接看代码缩进即可,就像 Python 一样。
3 基础表达式
一个高级语言一定具备这三个要素:
- 原子表达式 (primitive expressions):语言提供的最简单、最基础的元素。
- 组合方法 (means of combination):将原子表达式组合成复合元素的方法。
- 抽象方法 (means of abstraction):给复合元素命名,从而将其作为一个整体操作。
我们说汇编语言不是高级语言,因为它有非常弱的组合能力和抽象能力。例如 add $42 %eax 可以表示 eax + 42,但是要想表示 (eax + 42) * 3 就得写两条指令了,因为这个语言根本没有嵌套组合的能力。至于抽象能力,汇编中的函数(准确来说应该是 subroutine)更像是个 goto。而 Scheme 是非常高级的语言,因为它有非常强的组合能力和抽象能力,稍后我们可以看到。
3.1 原子表达式
原子表达式有这么几种:
- 数字。可以是整数
10、-12;浮点数3.14;有理数1/2、-3/5,形式是两个由/分隔的整数,注意中间不能有空格,因为这是一个原子。 - 字符串。由双引号标识,如
"Hello world"。 - 布尔。有两种,
#t和#f。 - 符号。也就是所谓的“变量”,或者说标识符。例如
pi,值为3.141592653589793;sqrt,为一个内建函数。不同于很多语言,Scheme 的符号不局限于字母、数字和下划线,例如reset!、*important*、+、1st-item都是有效的符号。
3.2 复合表达式
Scheme 中的复合表达式有两种,特殊形 (special form) 和函数调用。Scheme 函数调用的语法是 (function arg1 arg2 ...),让 S 表达式的第一个元素为函数,剩余元素为函数参数。例如下面的几个表达式都是函数调用:
1 | |
这里的 sqrt,+,* 都是函数名,分别执行平方根、加法和乘法操作。与其他大部分语言不同,Scheme 没有运算符,加减乘除运算、比较运算等都是函数。
对于初学者来说可能有些奇怪,但这种语法有很大的好处。首先表达式关系明确无歧义,程序员不需要记忆运算符优先级、是左结合还是右结合,且程序容易解析编译。使用方式统一,不会像 C 语言一样,乘法运算是 a * b,指数运算却是 pow(a, b)。不需要 C++ 那样复杂的运算符重载规则,直接定义一个名为 +、* 的函数即可。
下面给出了一些常用函数和调用方式:
1 | |
分号 ; 在 Scheme 中用作单行注释。
看到这里,你可能会以为表达式 (if (> a b) a b) 也是调用了一个 if 函数。但,实际上不是。对函数求值时,会先依次对各个参数求值,然后再调用函数。而对于 if 来说,当 (> a b) 为真时,只应该对 a 求值,不应该对 b 求值。反之,只应该对 b 求值。因此 if 不能是函数,应该是一个特殊形。
S 表达式就像是语法树的表示,而特殊形就是一种特定的语法,它定义这个语法有哪些子节点,含义分别是什么。下面给出了一些常用的特殊形和使用方式。
1 | |
4 定义函数
lambda 特殊形创建一个函数,形式为 (lambda (arg1 arg2 ...) body ...)。其中 (arg1 arg2 ...) 为参数列表,剩下的 body ... 为函数体,可由多个表达式组成,函数的返回值为最后一个表达式的值。我们通常结合 define 定义函数,下面给出了一个例子
1 | |
这个函数实现欧几里得算法,求两个整数 a 和 b 的最大公约数。函数参数列表是 (a b),函数体只有一个 if 表达式。if 表达式检查 b 是否为 0,如果 b 为 0 则返回 a,否则递归调用自身 (gcd b (remainder a b))。现在我们就可以调用 gcd 了:
1 | |
由于我们经常使用 define 和 lambda 定义函数,我们有一种简便的写法 (define (fname args ...) body ...) 等价于 (define fname (lambda (args ...) body ...))。因此 gcd 还可写成这样
1 | |
4.1 环境
函数可以嵌套定义。例如定义函数 prime? 判断一个数是否是质数,我们寻找能整除它的大于 1 的整数。如果找不到能整除它的整数,则它是一个质数
1 | |
prime? 所在的环境称为全局环境,iter 所在的环境为 prime? 的内部环境。define 执行的时候,会在它所处的环境中增加一个变量。当函数被调用时,会创建一个新环境,这个新环境继承函数定义时所在的环境;而函数的参数就在新环境中实例化。对表达式求值,会先在当前环境寻找变量的值,如果找不到则在上层环境寻找,依次类推。因此要考察一个函数的行为,必须考虑两个要素:这个函数的代码,和这个函数所在的环境。这两要素有时合在一起称为“闭包”。
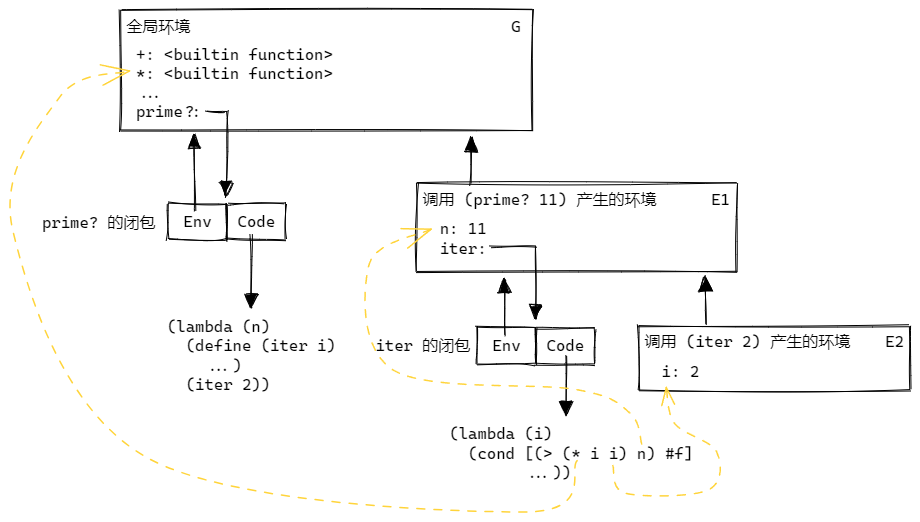
当我们在全局环境中执行 (prime? 11) 时,会有这么几步:
- 在全局环境中找到
prime?变量,发现它是一个函数,调用它。 - 读取闭包的 Env 字段,发现这个这个函数的环境是全局环境 G,因此创建一个继承 G 的新环境,记作 E1。
- 在 E1 中实例化参数,有
n: 11。 - 开始执行
prime?的代码。 - 执行
(define (iter i) ...),在 E1 中添加变量iter。iter是一个函数,所在的环境指向 E1。 - 执行
(iter 2),在 E1 中找到iter,发现它是一个函数,调用它。 - 发现这个函数的环境是 E1,因此创建一个继承 E1 的新环境,记作 E2。
- 在 E2 中实例化参数,有
i: 2。 - 开始执行
iter的代码。 - 执行到
(> (* i i) n):- 在 E2 找查找变量
*,找不到;然后再 E1 中找,还是找不到;最后在 G 中找到*是个内建函数。 - 在 E2 中查找变量
i,找到i: 2。 - 在 E2 中查找变量
n,找不到;然后在 E1 中找,找到n: 11 - …
- 在 E2 找查找变量
- …
- 执行
(iter (+ i 1)),可在 E2 中找到i: 2,在 E1 中找到iter。调用iter。 - 发现
iter所在的环境是 E1,因此创建一个继承 E1 的新环境 E3。 - 在 E3 中实例化参数,有
i: 3。 - 开始执行
iter的代码,以此类推。
这便是 Scheme 环境的运作机制。下一篇文章我们会实现这个机制,从而实现一个 Scheme 解释器。
Scheme 的函数是一等公民,我们可以将函数当作参数传递,也可以当成返回值返回。当函数被传递时,它所在的环境也将被传递。例如
1 | |
函数 f 返回一个函数,这个函数便保存了调用 f 时创建的环境。因此我们可以通过这个函数获取到调用 f 时传的值。后面我们可以看到这个机制有趣的应用。
4.2 let 与 let*
当我们需要中间变量时,例如计算 let 特殊形。
1 | |
let 的语法格式如下:
1 | |
它其实是个语法糖,等价于使用 lambda 创建一个函数,然后立刻调用它:
1 | |
let 有一个缺陷,就是定义后面的变量的值时不能引用前面的变量,也就是说 (let ([a 1] [b (+ a 1)]) b) 是非法的。于是我们有 let*:
1 | |
它也是一个语法糖,等价于
1 | |
let* 通过嵌套 let 实现,因此允许引用前面的变量。
5 数据结构
前面介绍了代码的组合和抽象,这一节介绍数据结构。这一系列文章只会用到非常简单的数据结构。
5.1 有序对和列表
为了构造复合结构,我们用 cons 构造有序对 (pair)。car 获取有序对的第一个元素,cdr 获取有序对的第二个元素。
1 | |
有序对可以任意嵌套,如 (cons (cons 1 2) (cons 3 4))。因为可以任意嵌套,所以理论上仅靠有序对就可以构造出任意复杂的数据结构。如果将有序对依次连接,就得到了一个链式列表:
1 | |
每个有序对的第一个元素 (car) 存储当前节点的值,第二个元素 (cdr) 指向下一个节点。最后一个元素的 cdr 为 '(),表示 NIL,链表的结尾。使用 list 函数可以快速创建一个列表:
1 | |
这样对于列表来说,car 用于获取列表的第一个元素,cdr 用于获取列表剩余的元素,而 cons 在列表头部插入一个元素。
1 | |
5.2 Quote
你可能会好奇 '() 和 '(2 3 4) 中的单引号 ' 是什么意思。回想一下第 1 节,S 表达式可以是原子表达式或列表。是的,这里的说的列表与 list 函数创建的列表是一个东西。也就是说,S 表达式
1 | |
本身就是一个列表。但是这个表达式会被 Scheme 解释成调用函数 1,传入参数 2, 3, 4。为了表示列表本身,我们用 quote 特殊形。quote 接受一个 S 表达式作为参数,不对这个表达式求值,而是直接返回它。下面是一些使用例子。
1 | |
由于 quote 十分常用,因此我们有一种简化形式。在任意 S 表达式前加上单引号 ' 表示对这个 S 表达式 quote。
1 | |
这有这非常重要的意义——意味着代码可以当作数据解析。这是其它非 Lisp 系语言不具备的能力。我们会在下一篇文章中大量使用它,这里我们先看一些简单的例子:
1 | |
这里的 cadr 和 caddr 是快捷函数。(cadr x) 等价于 (car (cdr x)),(caddr x) 等价于 (car (cdr (cdr x)))。这种命名也很容易记忆:中间的 a 和 d 分布表示依次调用 car 和 cdr。
我们知道列表由有序对构成。S 表达式使用括号表示列表,那么对于有序对这种更基础的元素,它如何表示呢?我们可以试验下:
1 | |
如果括号里的两个元素用 . 隔开,则表示这是一个有序对。但如果有序对的第二个元素被括号包裹,则会省略掉 . 和第二个元素的括号:
1 | |
因此 (cons 1 (cons 2 (cons 3 (cons 4 '())))) 的结果是 '(1 2 3 4),看上去像是个列表了。这种语法的好处是,既能体现列表是由有序对构成的(可以显式写成 (+ . (2 . (3 . ())))),又能让列表看上去很舒服(一般写作 (+ 2 3))。
5.3 Quasiquote 与 unquote
Scheme 还提供了一对方便我们构造特定列表的特殊形:quasiquote 与 unquote。它们同样接受一个 S 表达式作为参数。(quasiquote exp) 可简写为 `exp,(unquote exp) 可简写为 ,exp。与 quote 类似,quasiquote 也原样返回 S 表达式,但会对其中 unquote 的部分求值。
1 | |
还有一个类似的语法是 unquote-splicing,接受一个列表作为参数,(unquote-splicing list) 简写为 ,@list。它会对列表求值并展开:
1 | |
5.4 常用函数
这里介绍一些操作列表的常用函数。
pair? 判断是否是有序对
1 | |
list? 判断是否是列表
1 | |
symbol? 判断是否是符号
1 | |
null? 判断列表是否为空。
1 | |
memq 在列表中找到 car 等于给定值的有序对
1 | |
assoc 假设列表的元素都是有序对,找到有序对的 car 等于给定值的元素
1 | |
append 连接两个列表
1 | |
6 函数式编程
Scheme 倡导函数式编程,除了函数是一等公民外,还有一点就是“非必要不赋值”。到现在为止,我们还没有介绍赋值语句。对于命令式编程来说,不使用赋值语句连个有限 while 循环都写不出来。但是在函数式编程中,我们会熟练使用各种递归。
1 | |
虽然无法通过赋值改变变量,但是我们在可以调用函数时改变参数的值。有人可能会说递归性能差,因为需要消耗栈空间。确实,上面的代码在调用 (sum (cdr items)) 之前需要将 (car items) 的值压栈,以便 sum 返回后计算两者之和。但是我们只需要稍微修改一下写法:
1 | |
我们发现递归调用 (iter (cdr i) (+ s (car i))) 的返回值直接作为原函数 (iter i s) 的返回值,因此调用之前不需要压栈。这被称为尾递归。尾递归本质就是迭代,因为递归调用 iter 的过程就是不断迭代更新变量 i 和 s 的过程。
6.1 Accumulate
刚才我们定义了一个函数求所有元素之和。那么如果要求所有元素之积呢?我们可以定义一个 product 函数
1 | |
我们发现这个函数跟 sum 几乎一样。这两个函数都是给定一个初始值,依次与列表中的元素执行某个操作,然后依次迭代;只是初始值(一个是 0 另一个是 1)和操作(一个是 + 另一个是 *)不同。在 Scheme 中,函数可以当作值传递,而 + 和 * 都是函数。因此我们可以定义一个通用的函数,将初始值和操作作为参数传递进去:
1 | |
6.2 Map
与之类似的函数是 map。map 将列表中的每个元素通过一个给定的函数映射成新值
1 | |
map 还支持传多个列表,如 (map proc list1 list2 ...)。这些列表的长度要相等,并且列表的数量等于传入函数的参数数量。list1 的元素作为第一个参数传给 proc,list2 的元素作为第二个元素传给 proc,以此类推。
1 | |
如何实现 map 呢?Scheme 支持定义可变参数的函数。我们可以定义 (define (map proc . lists)),这种情况下 lists 便是一个包含剩余参数的列表。因为 (map proc list1 list2) 也可以写作 (map proc . (list1 list2))(见 5.2 节),因此不难理解这种写法。
反过来如果有 n 个参数存储在一个列表中,可以用 apply 将它们传给一个指定函数:
1 | |
这样我们可以实现 map 函数:
1 | |
Filter
从列表中过滤出符合要求的函数,可以用 filter。它接受一个返回布尔值的函数和一个列表作为参数,例如
1 | |
我们同样可以实现 filter:
1 | |
思考题:你能把
map和filter改成迭代(尾递归)的形式吗?
7 赋值
虽然函数式编程不鼓励使用赋值,但是很多场景完全不使用赋值会非常不方便,并且有些场景适当地使用赋值可以提升代码性能,简化一些实现。Scheme 使用 set! 特殊形执行赋值,使用格式是 (set! var val)。set! 先对 val 表达式求值,然后将值赋值给 var。例如:
1 | |
引入赋值会给系统增加很多不确定性。对于不使用赋值的函数,传入确定的参数必然得到确定的值,就像数学函数一样。而一旦引入赋值,就不一定了。可以看下面的例子:
1 | |
这里 (account 10) 调用了两次,传入相同的参数但是返回不同的值。4.1 节提到,当我们把函数当作值传递时,它所在的环境也会随之传递。因此我们可以把函数当作数据结构使用。上面的 account 是一个函数,也可以认为是一个数据。
Racket 中的有序对一旦构造好就不能修改。我们可以利用函数实现一个可修改的有序对:
1 | |
上面的例子可以认为是 Scheme 中的“面向对象编程”。mcons 返回的函数可视为对象,它通过传入的参数决定执行的操作,因此这种写法又被称为消息传递模式 (massage passing style)。mcons 可以称为构造器 (constructor),调用构造器的返回值获取“成员”,(mpair 'mcar) 这样的表达式就类似于 Java 中的 mpair.mcar。下面的代码展示了 mcons 的一些用法。
1 | |
8 总结
这篇文章介绍 Scheme 的一些基础内容,包括 S 表达式的构造、常用特殊形的用法、函数的调用与定义、对环境的理解、有序对与列表、常用函数的使用、赋值操作等内容。这些内容足以写出很多 Scheme 程序了。下一篇文章我们将用 Scheme 实现一个 Scheme 的解释器,实现本文介绍的绝大部分语言特性。
参考资料:
- [1] Structure and Interpretation of Computer Programs, Harold Abelson, The MIT Press
- [2] The Little Schemer, Daniel P. Friedman, The MIT Press