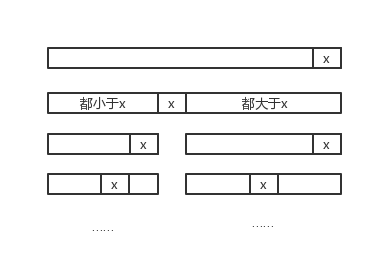
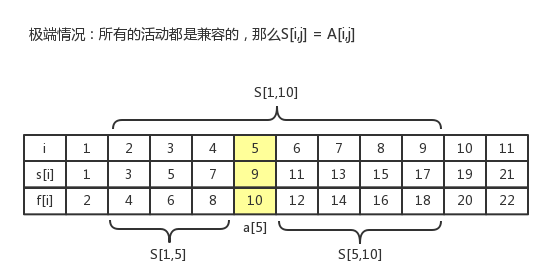
functionactivity_selector(s, f, i, j) local max_n = 0 for k = i + 1, j - 1do if s[k] >= f[i] and f[k] <= s[j] then local n = activity_selector(s, f, i, k) + activity_selector(s, f, k, j) + 1 if n > max_n then max_n = n end end end return max_n end
local save = {} functionset(i, j, n) ifnot save[i] then save[i] = {} end save[i][j] = n end functionget(i, j) ifnot save[i] thenreturnnilend return save[i][j] end
functionactivity_selector(s, f, i, j) local m = get(i, j) if m thenreturn m end
local max_n = 0 for k = i + 1, j - 1do if s[k] >= f[i] and f[k] <= s[j] then local n = activity_selector(s, f, i, k) + activity_selector(s, f, k, j) + 1 if n > max_n then max_n = n end end end set(i, j, max_n) return max_n end
functionactivity_selector(s, f) local c = {} for i = 1, #s do for j = 1, #s do ifnot c[i] then c[i] = {} end c[i][j] = 0 end end
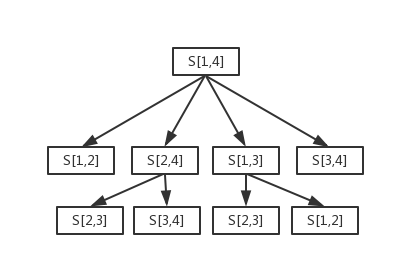
for j = 2, #s do for i = j - 1, 1, -1do local max_n = 0 for k = i + 1, j - 1do if s[k] >= f[i] and f[k] <= s[j] then local n = c[i][k] + c[k][j] + 1 if max_n < n then max_n = n end end end c[i][j] = max_n end end return c[1][#s] end
functionactivity_selector(s, f) local c = {} -- ...
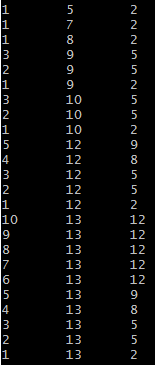
for j = 2, #s do for i = j - 1, 1, -1do local max_n = 0 local save_k for k = i + 1, j - 1do if s[k] >= f[i] and f[k] <= s[j] then local n = c[i][k] + c[k][j] + 1 if max_n < n then max_n = n save_k = k end end end if max_n ~= 0thenprint(i, j, save_k) end c[i][j] = max_n end end return c[1][#s] end
functionactivity_selector(s, f, k) local m = k + 1 while m <= #s and s[m] < f[k] do m = m + 1 end if m <= #s then return activity_selector(s, f, m) + 1 else return0 end end