详解寻路算法(1)-图搜索
1. 引言
寻路算法广泛应用在各种游戏中. 寻路算法要解决的问题是, 给定一个 “地图”(定义可行走区域), 一个起点, 和一个目标点, 求起点到目标点的最短路径. 解决寻路问题是一个复杂的过程, 涉及到若干个算法. 大体可以分为两个步骤: 1. 把 地图 抽象成 图. 这里的图指的是数学上的图
相比图搜索, 把地图抽象成图通常会比较复杂. 这篇文章先介绍介绍图搜索算法. 在下篇文章中, 我会介绍几种把地图抽象成图的方法.
图搜索算法有很多. 在寻路算法中, 主要用到 A* 算法. 这里我会先介绍 Dijkstra 算法, 然后引出 A* 算法. 稍后会看到, 这两种算法很相似: Dijkstra 算法总是搜索最近的, 适用于求解单源对所有点的最短路径; 而 A* 算法在 Dijkstra 基础上加上了启发式策略, 更适用于求解单源对单点的最短路径. 我会假设我们搜索的图都是带权重的无向图(因为寻路算法不会用到有向图), 因此你看到的算法跟教科书上的会有所不同.
2. Dijkstra 算法
2.1 松弛操作
Dijkstra 和 A* 算法都要用到松弛操作. 对于每个节点 v, 我们维持一个属性 v.d, 用于记录从源节点 s 到节点 v 的最短路径的长度上界(意思是最短路径有多长我们暂时不知道;但是肯定小于这个值). 我们称其为最短路径估计. 初始时, 原点的 最短路径估计 被赋为 0, 其余的都被赋为无穷大. 除此之外, 每个节点都有一个 parent 属性, v.parant 表示最短路径中 v 的前序. 初始时 v.parent 赋值为 None.
1 | |
对一条边 (u, v) 的的松弛过程为:
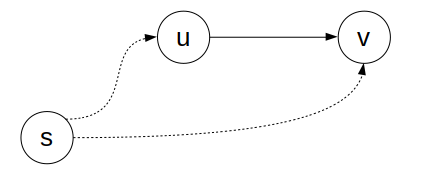
上图中虚线箭头表示一条路径, 实线箭头表示一条边. 如果路径 v.d 和 v.parent. 这个操作非常直观: 即找到了一条更短的路径, 就收缩上界.
1 | |
2.2 贪心策略
Dijkstra 算法是一个典型的贪心算法. 它总是维护一个优先队列. 初始时, 这个队列中只有源节点; 之后不断地从队列中取出最短路径估计最小的节点, 松弛其所有的临边, 如果某个节点 v 在松弛操作中改变了 v.d, 就把他加入队列, 直到队列为空. 代码如下:
1 | |
你可能会发现这种实现会导致同一个节点入队两次. 但这篇文章指出, 这样做是没问题的 : > I eliminate the check for a node being in the frontier with a higher cost. By not checking, I end up with duplicate elements in the frontier. The algorithm still works. It will revisit some locations more than necessary (but rarely, in my experience, as long as the heuristic is admissible). The code is simpler and it allows me to use a simpler and faster priority queue that does not support the decrease-key operation. The paper “Priority Queues and Dijkstra’s Algorithm” suggests that this approach is faster in practice.
下面展示了算法的执行过程:
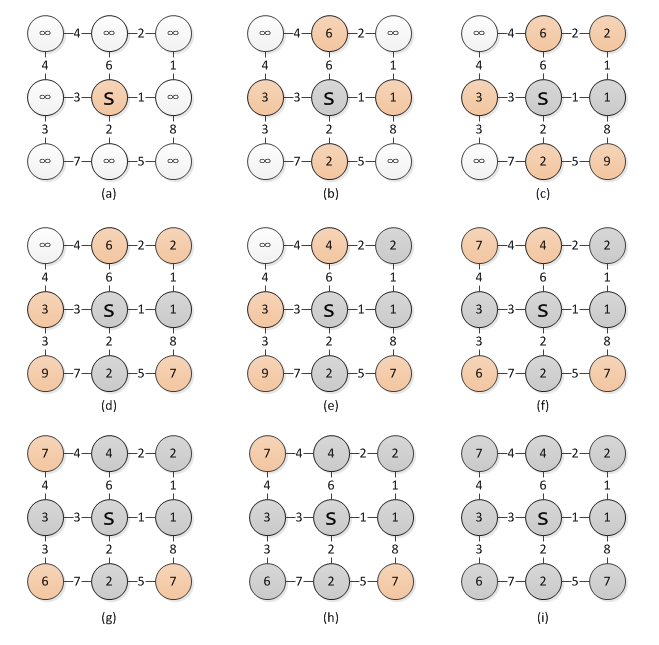
执行循环前的状态如图(a)所示; 之后 (b) - (i) 展示了循环的执行过程: 每次从队列(即所有的橙色节点)中选取 v.d 最小的节点, 对其所有临边执行松弛操作.
3. A* 算法
3.1 启发式搜索
在 Dijkstra 算法中, 我们求出了单源对所有点的最短路径. 而在寻路算法中, 我们往往只需要求出单源对单点的最短路径. 为了完成这一优化, 我们采用一种启发式的策略: 从源节点开始, 有倾向性地向目标节点的方向搜索节点. 为了描述这个 “倾向性”, 我们定义一个启发函数, 它可以告诉我们如何接近目标点:
1 | |
在启发函数中, 我们简单地求算了两点之间的直线距离; 这样通过调用启发函数, 我们可以求得距离目标点最近的点. 现在我们试试这样做: 不再每次搜索 v.d 最小的节点, 而是每次搜索距离目标点最近的点, 即 heuristic(v, g) 最小的点.
1 | |
这个算法被称为 贪婪优先搜索(Greedy Best First Search). 与 Dijkstra 类似, 它也总是维护一个优先队列; 不同的是, 这个优先队列是根据离目标点的距离进行排序, 而不是最短路径估计. 这样一来, 算法就会不断地朝这目标点的方向进行搜索, 直到搜索到目标点. 我们来看看它是怎么工作的:
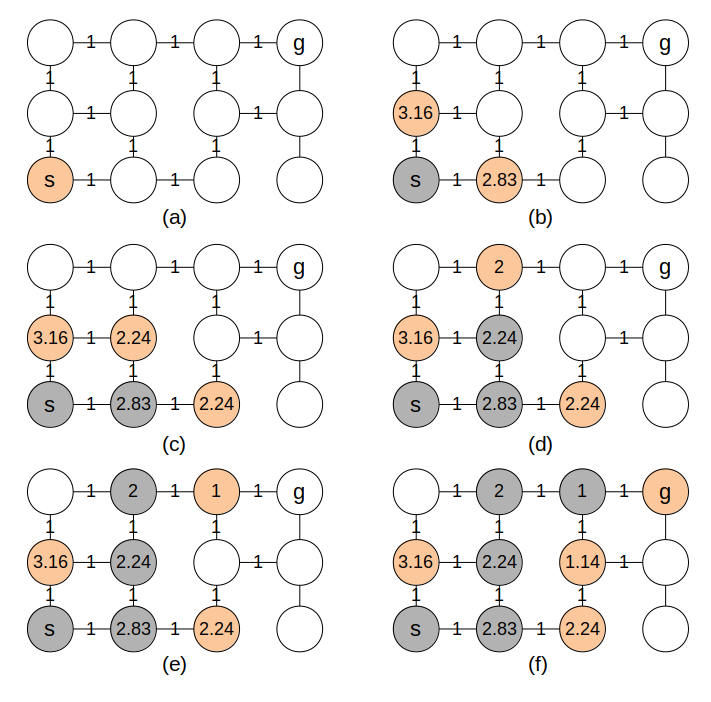
图中节点上的数字表示节点距离目标点的距离. 可以看到, 这个例子的图中一共有12个节点, 而我们只迭代了6次就找到了到目标节点的最短路径. 这便是启发式策略的好处. 但是这样一定能找到最短的路径吗? 去掉两条边试试:
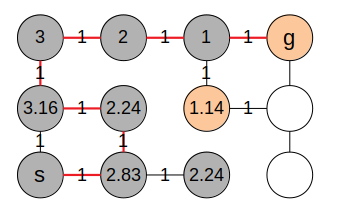
可见, 完全使用启发式策略的算法并不能保证总是获得正确的结果. 那么有没有既能保证获得正确的结果, 又有贪婪优先搜索的高效呢? 答案是肯定的. 这便是 A* 算法.
3.2 A* 算法
Dijkstra 算法保证能找到最短路径, 但是却探索了所有的节点, 浪费了时间; 而贪婪优先搜索只朝着目标节点探索, 却不能保证结果的正确性. 把这两者相结合, 便是今天的主角 – A* 算法了. 下面是 A* 算法的代码, 你会发现它和 Dijkstra 算法的代码非常相似:
1 | |
这样就好啦! 可以说与 Dijkstra 唯一的不同就是优先队列不再只以 v.d 作为排序依据, 而是 v.d + heuristic(v, g). 这意味着不会每次都取 v.d 最小的点, 一个节点离目标点越近, 就越有机会被优先考虑. 来看看它是怎么工作的:
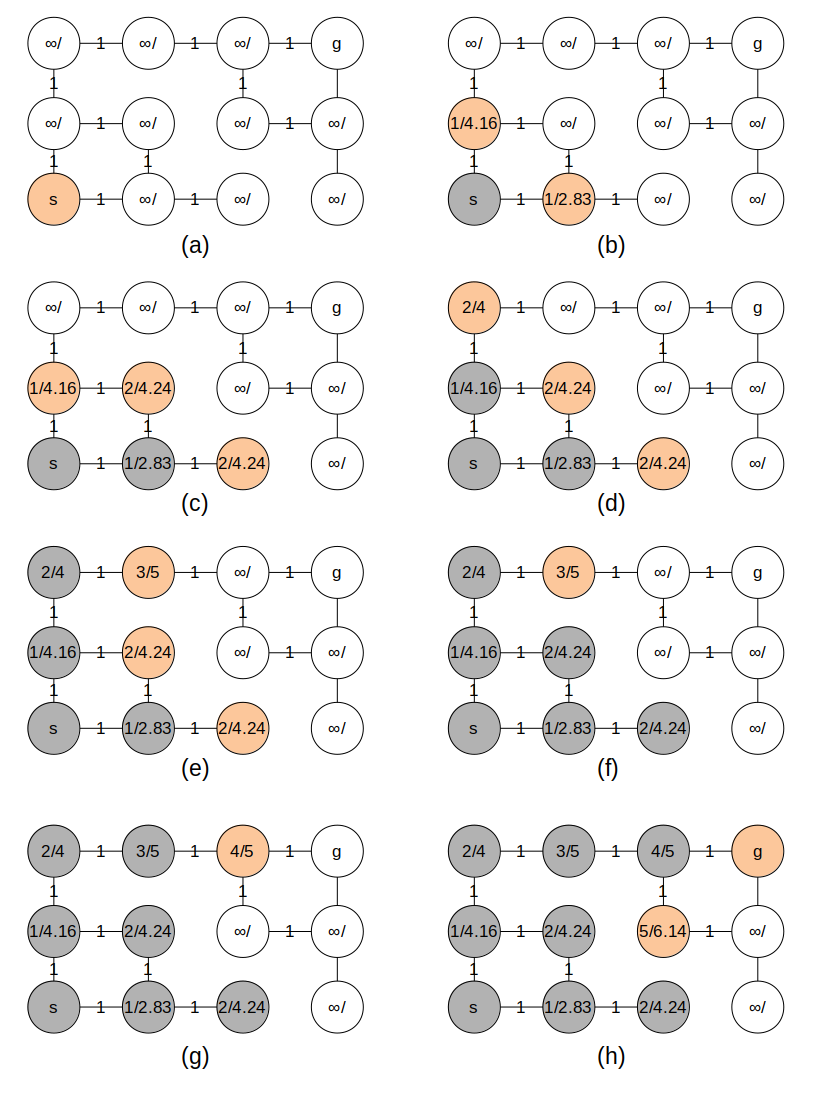
图中用斜杠隔开的两个数字分别是 v.d 和 v.d + heuristic(v, g). 图(a)展示了循环前的状态; 之后的 (b) - (h) 展示了每次循环的状态: 每次从队列(即所有的橙色节点)中选取 v.d + heuristic(v, g) 最小的节点, 对其所有临边执行松弛操作.
可以看到, 与贪婪优先搜索不同, A* 算法能够保证结果的正确性; 此外又比 Dijkstra 算法高效. 事实上, 只要启发式函数 heuristic(v, g) 的返回值不超过真实最短路径 heuristic(v, g) 的返回值越接近真实最短路径 heuristic(v, g) 的返回值总为 0, 则 A* 算法退化为 Dijkstra 算法.
4. 总结
本文介绍了两种图搜索算法: Dijkstra 算法 和 A* 算法. 在寻路算法中, 主要使用的是 A* 算法进行图搜索, 因此本文的主角实际上是 A* 算法, 讲 Dijkstra 算法是为了引出 A* 算法, 并且说明 A* 算法为什么要这么做.
本文是笔者在这个网站 Red Blob Games 学习寻路算法之后做的一个总结. 同时笔者强烈推荐大家去看 Red Blob Games 上的教程, 不仅图文并茂, 而且可以与之互动; 它讲解的寻路算法是我见过所有的寻路算法讲解中讲得最明白的.
参考资料: - Introduction to the A* Algorithm - Implementation of A* - 算法导论第三版, 机械工业出版社